
Lo que debe saber sobre despliegue y arquitecturas de solución en Inteligencia Artificial
Este artículo aborda las consideraciones de arquitectura para el despliegue y arquitecturas de solución en AI. Está orientado a personas o equipos que se encuentren interesados en iniciar un proyecto de dicha naturaleza, e incluso también es una guía para aquellos que consideren iniciar en un ambiente de pruebas.
Es importante no perder de vista que la inteligencia artificial hace parte de un sistema más grande y que entre sus funciones está apoyar objetivos de negocio específicos. Desde luego es una ciencia que debe ser integrada con otros sistemas nuevos y legados. Para este caso, vale la pena mencionar que la tarea del científico de datos debe incluir estas preocupaciones.
La inteligencia artificial se centra en IDENTIFICAR INSIGHTS SOBRE LOS DATOS Y ENTRENAR MODELOS que permitan hacer inferencia sobre escenarios definidos. Las técnicas usadas en este tipo de estudios están cobijadas bajo el término “Data Science”.
Ciclos de experimentación en inteligencia artificial
Un ciclo de experimentación en inteligencia artificial se compone de tres acciones fundamentales: idear, programar y experimentar. Los Jupyter Notebooks, por ejemplo, son una herramienta que permite apoyar estos ejercicios de experimentación en ambientes en la nube. En términos generales, los notebooks son documentos que contienen una mezcla de markdown (Lenguaje de marcado para documentación) y código ejecutable en vivo en lenguajes de programación como Python o R.
Estos ejercicios son interesantes, debido a que permiten generar resultados con gran agilidad, pero pierden visibilidad por numerosas razones, la principal de ellas es que este tipo de ambiente es experimental. Por lo anterior, haré hincapié en algunas consideraciones importantes que hay que tener en cuenta a la hora de desplegar soluciones de inteligencia artificial, con el fin de que se conviertan en una herramienta útil de las organizaciones que deseen implementar esta ciencia.
Soluciones de inteligencia artificial
Un modelo de machine learning eventualmente se convierte en una caja negra que, dado un input de datos, genera un output con la inferencia (que puede ser una predicción, una clasificación, etc.). Esto pasa ya sea, aplicado a un sistema de predicción como el clásico ejemplo de los precios de las viviendas, que dadas características como el tamaño (área construida o habitable), el número de baños, la localización geográfica entre otras cosas permite predecir el precio del inmueble. También podemos verlo en los ejemplos de visión por computadora como el clasificador de gatos y perros que recibe como input una imagen y determina si contiene un gato o un perro. Así mismo, podemos encontrarlo en un chatbot que recibe el input de conversación de un usuario y retorna la respuesta adecuada de acuerdo a su intención.

{kind=link}
Uso y necesidad de usuarios de soluciones AI
Teniendo en cuenta este hecho, es más fácil entender qué se quiere hacer con el despliegue de una solución de AI. Ahora puede pensar más en la forma del input de su modelo, ¿se trata de un sistema de respuesta inmediata, como en un chatbot, con una entrada de texto único? O ¿puede ser un sistema de conteo, donde el usuario puede cargar múltiples imágenes para ser procesadas en batch (procesamiento por lotes)?. Lo anterior pone en evidencia que independientemente del modelo, esta es una característica que está definida por el caso de uso y la necesidad de sus usuarios.
Con esto en mente, es momento de pensar en los recursos necesarios para ejecutar la predicción. ¿Su modelo requiere procesamiento que usa de forma intensiva los recursos de hardware?. Si es así, deberá ejecutar estos procesos sobre la GPU (unidad de procesamiento gráfico). ¿Está su modelo preparado para usarla? ¿Requiere que su predicción se haga en tiempo real? ¿Cuántos usuarios van a realizar predicciones? ¿Cuál es el volumen de los datos que van a pasar por el modelo?
Así, empezamos a encontrar algunas soluciones a las necesidades que de pronto ya está empezando a adoptar y que no tienen relación al entrenamiento de un modelo de machine learning, de redes generativas o de cualquier otra técnica de Inteligencia Artificial. Como lo dije anteriormente, un chatbot requiere respuesta inmediata y un manejo del estado de la intención. En este caso se hace preferible el uso de aplicaciones con estado. Si desarrolló su modelo en Python puede usar un framework como Flask o Django, también puede manejar el estado de la conversación desde el frontend y desplegar su modelo como un servicio sin estado al que debe recordarle constantemente el flujo de la conversación.
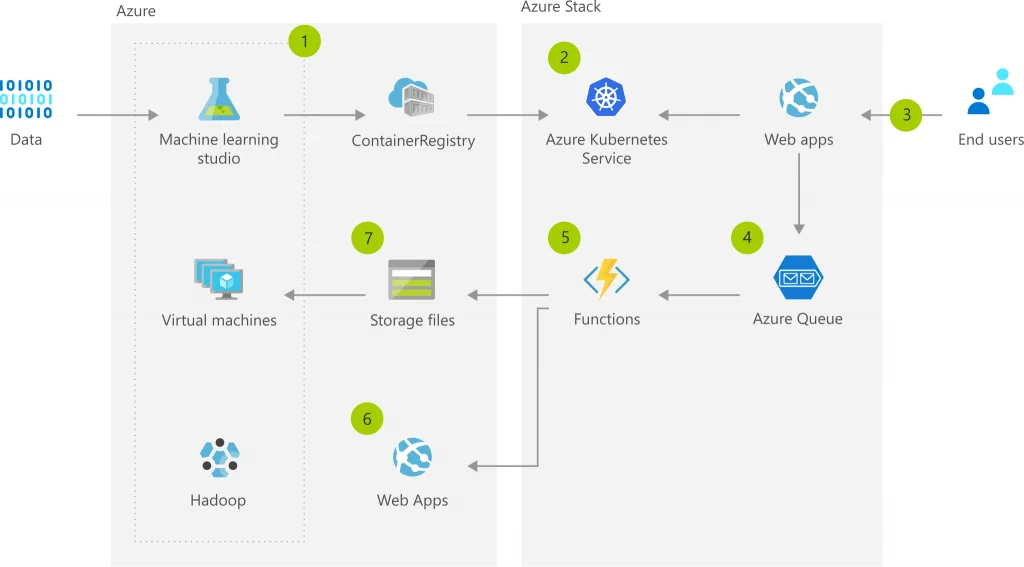
¿Qué es aconsejable para cada modelo?
En modelos de predicción y clasificación que no son intensivos en cómputo, es aconsejable manejar servicios web. Los contenedores, vistos como unidades de software que empaqueta el código y sus dependencias, son una forma fácil de desplegar este tipo de modelos en instancias que pueden ser escaladas vertical y horizontalmente. Normalmente los contenedores son desplegados sobre servicios de virtualización de costo continuo.
Si su modelo es para un uso más granular o si se trata de un modelo que se ejecuta como una tarea programada, se recomienda el uso de funciones en la nube. Las funciones en la nube son unidades de cómputo que se cobran por segundos de ejecución, en este tipo de servicios la preocupación no radica en la infraestructura, sino en la eficiencia del código. Si se diera el uso continuo en el tiempo de este servicio, el costo sería mucho más alto que el de una virtualización tradicional.
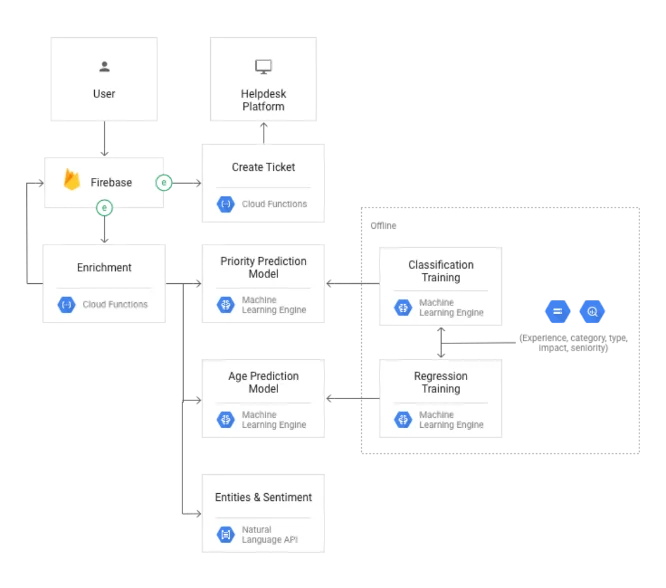
Clusters de predicción
Por último, suponga que quiere hacer predicciones sobre los datos haciendo uso de un modelo con altos requerimientos computacionales, donde probablemente la predicción toma bastante tiempo en terminar. Una buena solución para este tipo de requerimientos es la creación de clusters de predicción, que no son más que grupos de máquinas virtuales que cumplen las características necesarias para la ejecución del modelo. Estos clusters son fácilmente escalables horizontalmente. La idea de lo anterior es registrar la tarea de predicción en un datastore (Base de datos, cola, etc.) de su elección, un nodo del cluster se apropia de la tarea y escribe el resultado de la predicción asociado a esta tarea.
Este tipo de arquitecturas de solución también es muy usado para la predicción en batch, por medio del uso de colas y definición de servicios sin estado. Las peticiones de los usuarios pueden cambiar de un servidor a otro. En este caso los servidores, nodos o contenedores de inferencia son vistos como trabajadores cuya función es sacar la siguiente tarea de la cola para hacer la inferencia. Nuevamente el resultado de la inferencia debe ser persistido con el registro de la tarea invocada.
Despliegues en la nube
Los proveedores de infraestructura en la nube como Azure, Amazon y Google tienen frameworks de desarrollo de machine learning, estos frameworks tienen las herramientas adecuadas para lograr este tipo de despliegues en la nube y se puede llegar a resultados muy interesantes de forma ágil. Sin embargo, la herramienta más útil es el registro de modelos. Un registro de modelos es simplemente un repositorio, donde es posible versionar y aprovisionar los modelos de machine learrning para ser desplegados fácilmente.
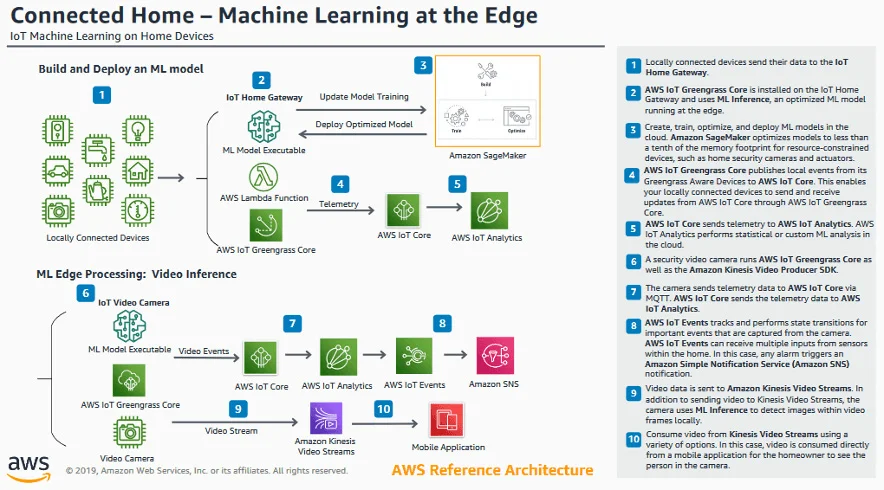
On the edge
Hablamos del despliegue de modelos en infraestructuras en la nube, pero también se puede deplegar modelos “on the edge”. Este tipo de despliegues es altamente usado en arquitecturas para IoT y para dispositivos móviles. Un ejemplo de este tipo de despliegues es el reconocimiento facial, que puede ser desplegado en dispositivos móviles o en dispositivos como Raspberry o Jetson.
Se trata del entrenamiento de modelos de forma tradicional y una conversión del modelo para el despliegue en dispositivos con menor capacidad computacional o con requerimientos energéticos especiales. Esta conversión del modelo desfavorece ligeramente la precisión de la inferencia y se hace posible por medio de librerías como Tensorflow. Sin embargo, no todos los modelos pueden ser convertidos y deben ser muy bien diseñados para lograr este cometido.
En el caso de Computer Vision, la mayoría de estos modelos detectan características genéricas de lo que se desea identificar o son modelos de clasificación aun limitados. No es común ver modelos que clasifiquen una gran variedad de personas en imágenes y que estén disponibles para todos los dispositivos móviles del mercado.
En conclusión
Para finalizar, quiero destacar que las ideas presentadas anteriormente, no son inherentes a esta área de trabajo, por el contrario, funcionan para todos los procesos que puedan consumir una cantidad prudente de recursos computacionales y de tiempo. De tal forma que, espero que pueda llevar a la realidad con mayor claridad las estrategias de su próximo proyecto de despliegue de AI. De la misma manera espero que tenga mayor capacidad de respuesta a inconvenientes que se presenten en la implementación de este.

VISIT OUR KNOWLEDGE CENTER
We believe in democratized knowledge
Understanding for everyone: Infographics, blogs, and articles
Let’s tackle your business difficulties with technology
” There’s a big difference between impossible and hard to imagine. The first is about it; the second is about you “

Marvin Minsky, Professor pioneer in Artificial Intelligence