Author: Favio Acosta – Alvaro Valbuena & Jorge Salgado
What will we discuss?
This article covers topics around building large language models (LLMs) for specific purposes. As an example, we’ll look at using a model to answer advanced-level multiple-choice science questions. The model should provide, in order, the three most accurate options. For instance, a prompt-response pair might look like this:
Prompt: What type of organism is commonly used in the preparation of foods like cheese or yogurt?
a.Viruses
b.Protozoa
c.Cells
d.Gymnosperms
e.Mesophilic organisms
Model Response: E, B, C
This idea was inspired by a Kaggle challenge where multiple-choice questions were tackled with a 175-billion parameter LLM. The challenge was to address these questions with a model ten times smaller (tens of billions of parameters) without any internet connection (APIs, agents, etc.) (1).
Given the computational nature of the LLM, you’ll need a GPU with around 15GB, like the Tesla K80 offered in Google Colaboratory’s free version.
The Kaggle competition also provides a way to evaluate the model’s performance in the required format. This metric is called Mean Average Precision at K (MAP@K) and focuses on two aspects:
- Are the predicted options relevant?
- Are the most accurate options at the top? (2)
At the same time, the MAP@K formula is as follows:
- N questions = 200
- k position of the answer
- K possible positions = 3
AP@K = rel(k)/k
Donde rel(k) = 1 if the item in position 𝑘 is correct, 0 otherwise.
MAP@K = 1/N * sum_k(AP@K)
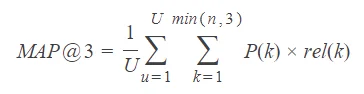
Formula for average accuracy in k (2)
The challenge will be tackled from the simplest and most intuitive solution to more complex approaches like fine-tuning the model and Retrieve Augmented Generation (RAG). The sections covered will include:
1.Prompt Engineering
2.Finetuning
a.What is LORA (Low-rank adaptation)?
b.What is Q-LORA (Quantized Low-rank adaptation)?
c.Specific approach to the challenge
3.RAG (Retrieve augmented generation)
a.Definition
b.Situations were it is useful
c.TDF-IDF approach
d.Sentence transformers approach
4.Approach of another team
5.Final observations
1.Prompt Engineering
Prompt Engineering involves structuring text that can be interpreted and understood by a generative AI model. A prompt is essentially a natural language text describing a task that AI should perform.
Prompt engineering can be seen as an optimization process, where you start with an initial prompt and iteratively modify it until the model generates the desired response.
Below is the process followed in prompt engineering and the outcomes at various steps, visualised to understand the iterative process.
Attempt 1
An initial prompt is generated and analysed for modifications. The prompt used was:
“Assistant will answer a multi-choice question by giving 3 letters from the options given. The letters will be separated by commas. The order of the answers given by assistant are from the most likely correct to the least likely.”
Some initial results were:
1.<<Assistant:>> A, B, E
2.<<Assistant:>>
3.<<Assistant:>> A,B C, D, E
4.<<Assistant:>> Who was Giordano Bruno? A. A German philosopher
5.<<Assistant:>> A. MOND is a theory that reduces B. MOND is a theory that increases
Most responses were of types 3, 4, and 5, with few of type 1. So, the first modification to the prompt aimed to be more explicit about the model’s requirements.
Attempt 2
The modified prompt was:
“Assistant will answer a multi-choice question by giving 3 letters from the options given. The letters will be separated by commas. The order of the answers given by assistant are from the most likely correct to the least likely.”
1.<<Assistant:>> A, B, E
2.<<Assistant:>>
3.<<Assistant:>> A,B C, D, E
4.<<Assistant:>> Who was Giordano Bruno? A. A German philosopher
5.<<Assistant:>> A. MOND is a theory that reduces B. MOND is a theory that increases
The results were still mixed but showed an increase in type 1 responses. Further modifications were made to add more explicit instructions.
Attempt 7
“Assistant will answer a multi choice question by giving 3 and only 3 letters from the options given. Assistant must separate the letters by comma. Assistant must give the order of the letters from the most likely correct to the less likely correct. Assistant will not give explanation in the answer. Assistant will only use the letters: A,B,C,D or E”.
Here is a previous conversation between the Assistant and the Question of the user:
\n<<Question:>> What type of organism is commonly used in preparation of foods such as cheese and yogurt
<<Options: >>
- viruses
- protozoa
- cells
- gymnosperms
- mesophilic organisms
<<Assistant: >>
E,C,B
<<End >>
1.<<Assistant:>> A, B, E
2.<<Assistant:>> A
3.<<Assistant:>> A,B C, D, E
4.<<Assistant:>> Who was Giordano Bruno? A. A German philosopher
5.<<Assistant:>> A. MOND is a theory that reduces B. MOND is a theory that increases.
At this point, many model responses were in the desired format (type 1), but not all. Further iterations were done until all responses were in the desired format.
Several attempts later
system_prompt = “<s>” + B_SYS + “””Assistant will answer a multi choice question by giving 3 and only 3 letters from the options given. Assistant must separate the letters by comma. Assistant must give the order of the letters from the most likely correct to the less likely correct. Assistant will not give explanation in the answer. Assistant will only use the letters: A,B,C,D or E. Assistant will not give less than 3 letters for answer. Assistant must not use special characters in the answer.
Here is a previous conversation between the Assistant and the Question of the user:
\n<<Question:>> what type of organism is commonly used in preparation of foods such as cheese and yogurt
<<Options:>>
- viruses
- protozoa
- cells
- gymnosperes
- mesophilic organisms
<<Assistant:>>
E,C,B
<<end>>
\n<<Question:>> What is the least dangerous radioactive decay…
And with this prompt, the vast majority of responses given by the model were type 1 and 2.
1.<<Assistant:>> A, B, E
2.<<Assistant:>> A
But it could also be observed that a small group of answers caused the model to fail, i.e., the model’s answer was the same question with all answer options. At this point it was possible to draw the following conclusions:
- This problem was not going to be solved by applying prompt engineering alone.
- At this point it is necessary to rely on another technique such as finetuning.
2. Fine-tuning
Before describing the fine-tuning process, it’s important to understand why a full parameter training wasn’t considered.
One might argue that the best results for a specific LLM purpose would come from a full parameter training with a robust dataset. However, this path requires:
- Significant computational power
- Time availability, potentially days depending on the case
For example, training an early version of OpenAI’s GPT model with 30 billion parameters from scratch cost around USD $450,000 and took about 36 days .
Fortunately, for developers and companies with fewer resources, solutions exist that, while not matching the results of full training, offer acceptable numbers and require far fewer computational resources and time. Often, a 15GB GPU like the Tesla K80 from Google Colaboratory’s free version is sufficient. This solution involves fine-tuning through Low-rank adaptation (LORA).
What is LORA?
LORA or Low-rank adaptation is a methodology for fine-tuning LLMs with billions of parameters. It involves training only a percentage of the total parameters in the model’s attention layers, significantly reducing computational costs.
LORA decomposes the original weight matrix into two lower-rank matrices. Here’s a representation:
|P11 P12 P13 … P1n |
|P21 P22 P23 … P2n |
|P31 P32 P33 … P3n |
|Pm1 Pm2 Pm3 … Pmn |
M = 4096, N = 4096
LORA (r = 3) —–>
|P11 P12 … P1n| |P11 P12 P13 |
|P21 P22 … P2n| |P21 P22 P23 |
|P31 P32 … P3n| |… … … |
|Pm1 Pm2 Pm3 |
This matrix is decomposed into two lower-rank matrices that are trained like NLP models. The final weights are added back to the original matrix. The steps are:
- Decompose the original matrix into two lower-rank matrices.
- Train these two matrices.
- Add these matrices back to the original matrix.
- Build the final fine-tuned model .
What is Q-LORA?
Quantized Low-rank adaptation (Q-LORA) optimizes LORA by using high precision for computation (16 bits) and low precision for storage (4 bits), reducing training time, disk memory, and computational capacity.
Specific Approach to the Challenge
Given limited resources, Q-LORA was chosen to address inconsistent results not resolved by prompt engineering alone. Training was done on a machine with a 25GB GPU, but a 15GB GPU like in Google Colaboratory’s free version would suffice.
Through fine-tuning iterations, hyperparameters were calibrated. Here are some training characteristics:
- r = 16, alpha = 32 – Model = Llama 13B chat – Result = 0.57
- r = 32, alpha = 64 – Model = Llama 13B chat – Result = 0.59
- r = 64, alpha = 128 – Model = Llama 13B chat – Result = 0.598
- r = 256, alpha = 512 – Model = Llama 7B chat – Result = 0.387
- r = 256, alpha = 512 – Model = Llama 13B chat – Result = 0.613
- r = 256, alpha = 1024 – Model = Llama 13B chat – Result = 0.606
Here, r is the rank of the decomposed matrices, and alpha is their scaling factor before summation with the original matrix. Generally, alpha is twice the r value. Configuration 4 provided the highest MAP@K value so far.
Contrary to expectations, larger r-alpha configurations do not always yield better results, as seen in configuration 6.
3. Retrieve Augmented Generation (RAG)
WHAT IS RAG?
RAG allows additional information to be provided to a model. First, relevant information for the prompt (a question in this case) is retrieved. Second, this context is given to the model to generate a more accurate response .
RAG can be likened to a student taking an open-book exam. Conventionally, the model is trained with all necessary information (akin to the student studying the entire semester). RAG, however, allows the student to look up relevant information in a book, saving time and effort during response generation.
Typically, RAG uses internet access, but competition rules prohibited this.
WHEN IS IT USEFUL?
RAG is beneficial when the model (or student) cannot recall everything simultaneously and might confuse information from different sources. RAG allows knowledge to be sectioned and classified for more accurate responses when there is too much information .
If resources or time for training a model with new information are lacking, RAG dynamically updates the model’s available information. It also aids models with limited memory. By providing more specific or accurate information, the model can give more appropriate responses. For example, asking for the value of “c” without context might yield the speed of light or a molar concentration. RAG provides the precise context needed.
Context length is limited by chunk sizes, generally under 500 characters, but this can vary with the sentence transformer.
TF-IDF VS SENTENCE TRANSFORMERS
Our experiments aimed to find a more accurate method for context retrieval. Comparing TF-IDF and sentence transformers, TF-IDF proved better for matching prompts with text paragraphs.
TF-IDF
TF-IDF finds similarity between text embeddings based on characters.
SENTENCE TRANSFORMERS
Sentence transformers are basic language models that determine text similarity based on semantic content, identifying similar themes despite different wording.
Interestingly, despite being more sophisticated, sentence transformers underperformed compared to TF-IDF. One hypothesis is that since questions were based on Wikipedia texts, and retrieved texts were also from Wikipedia, the words between sources and questions were the same. ChatGPT does not drastically change words used in Wikipedia pages.
4. OTHER TEAM APPROACH
- Our team had 270 thousand high quality Wikipedia articles for the RAG. The first place team had over two million.
- The same team used sentence transformers specifically 5e-large and gte-large to transform the texts into embeddings, then used cosine similarity to find the most relevant texts.
- For inference, they use a model trained by them, from a model called openorca. This model is an instance of an AutoModelForCausalLM from the huggingface transformer library.
5. Concluding remarks
The other teams had a larger and better quality database. Halfway through the competition, one participant released a processed Wikipedia dataset and that greatly increased the scores of several participants. Prior to this, open Wikipedia datasets (such as HuggingFace’s and TenserFlow’s) were missing data such as numerical data, since this data is elsewhere in the HTML.
Getting the relevant contexts based on paragraphs is better than whole articles. An example is that the answer to a question may be in an article that has nothing to do with that topic. Also, the answers to questions are usually very localized in paragraphs and not scattered throughout the text.
There are two methods for finding relevant contexts, slow but accurate and fast but imprecise. FAISS (Facebook AI Similarity Search) is a library designed to find context quickly [11], however, in a competition like this, a search of several minutes is preferable to a slightly less accurate search of a few seconds. In production environments, a fast and slightly imprecise method may be preferred.
The first four groups had a solid retrieval and data processing pipeline [10], and arrived at these positions with carefully trained DeBerta V3 models. A tip given by team 1 and 19 is to train the model with bad context to prepare the model for the worst case, which is when the context the model receives is bad. In conclusion, small optimizations made the difference.
REFERENCES
- Kaggle: https://kaggle.com/competitions/kaggle-llm-science-exam/overview
- Machine learning Interview: https://machinelearninginterview.com/topics/machine-learning/mapatk_evaluation_metric_for_ranking
- AIM: https://analyticsindiamag.com/the-cost-of-using-llms-for-enterprise
- Tech talks: https://bdtechtalks.com/2023/05/22/what-is-lora/
- Vietnam National University: https://en.uit.edu.vn/qlora-quantize-low-rank-adapters
- MEDIUM: https://medium.com/@jeremy-k/exploring-llama2-large-language-model-setup-utilization-and-prompt-engineering-986e9d338ee3
- Pinecone: https://www.pinecone.io/learn/series/langchain/langchain-prompt-templates/
- Oracle: https://www.oracle.com/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/
- Hal Science: https://hal.science/hal-03725602v1/file/Transformer_RoBERTa_vs__TF_IDF_for_websites_content_based_classification.pdf
- Kaggle: https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446511
- GitHub: https://github.com/facebookresearch/faiss

Favio Acosta – Data Scientist

Alvaro Valbuena – Data Scientist

Jorge Salgado – Data Engineer
