
Authors: Laura Mantilla – Santiago Ferreira
The purpose of this article is to show the results and process of our work, where we had the objective of creating an abstractive question-answering system. This means that we wanted to feed an AI with a specific topic, and this AI would be able to answer questions about such topic eloquently, responding in a way that does not use pre-imputed answers but can create an answer depending on the text it was trained upon.
To do this, we will first show some fundamental concepts and tools necessary to understand our process: large language models, Fireworks AI, LangChain, Embedingg generation models, Pinecone and Retrieval Augmented Generation. After this, we will show the methodology used to combine these things into our system and workflow. Lastly, we will show our results and conclusions.
We have reached a Minimum Viable Product (MVP) without requiring substantial computational power or financial resources.
Foundations (Key Concepts)
Large Language Models
A Large Language Model (LLM) is an artificial intelligence (AI) model designed to understand and generate human-like text. These models are trained on vast amounts of textual data from the internet, books, articles, and other sources. The training process involves exposing the model to a diverse range of language patterns, structures, and contexts to learn to predict what comes next in a given sequence of words. LLMs have several uses, for example, chatbots, content creation, and language transformation; in programming, these models can help complete or correct code. (Karpathy, A. (2023)).
Some examples of LLM’s are Meta’s LLaMa, Google’s PalM2, and OpenAI’s GPT-3 and GPT-4, which are the models that Chat GPT runs.
To create such models, it is necessary to use a great deal of data. Andrej Karpathy, a founding member of OpenAI, emphasises that the pre-training phase of the training stages of a GPT assistant takes most of the computation efforts and time. This process can take months to complete and thousands of GPUs. After this process ends, you will have the base model; you’ll have to use supervised fine-tuning, reward modelling and reinforcement learning to match your specific needs. (Microsoft Developer & Karpathy, A. (2023)).

Image1: Taken Karpathy, A. (2023) State of GPT
FIREWORKS AI
Fireworks.ai is a powerful platform designed to facilitate the utilisation of large language models (LLMs) for solving complex challenges. This platform is a valuable resource offering the tools to run, fine-tune, and share LLMs for optimal problem-solving. (LangChain Blog. (2023)).
This platform provides access to high-performance open-source models (OSS), efficient LLM inference, and state-of-the-art foundational models that can be fine-tuned to meet specific requirements. (LangChain Blog. (2023)).
- Integration with LangChain:
Integrating Fireworks.ai models into the LangChain Playground simplifies access to the best-performing open-source and fine-tuned models, enabling developers to create innovative LLM workflows. (LangChain Blog. (2023)).
LangChain
LangChain is an open-source framework that makes developing abstractive question-answering (QA) systems easy. The framework provides a variety of components that can be used to create QA systems of different types.
LangChain can be used to create abstractive question-answering systems in the following ways: [4]
- To generate documents: LangChain can be used to generate text documents, which can be used as answers to open or challenging questions.
- To search for information: LangChain can be used to search for information from various sources, including the web, databases, and documents. This information can be used to support the answers generated by LangChain.
- To measure similarity: LangChain can measure the similarity between generated answers and found information, ensuring that answers are accurate and relevant.
Embedding Generation Models
Embedding generation models are essential in modern natural language processing (NLP) and information retrieval systems. These models are designed to transform textual data, such as sentences or documents, into high-dimensional vector representations.
These vectors capture the semantic information, context, and meaning of the text, allowing for similarity comparisons, clustering, and various forms of analysis. This functionality is crucial for applications like search engines, recommender systems, and abstractive question-answering systems. (Hugging Face. (2022)).
PINECONE
Pinecone is a text vector database. A text vector database is a collection of words and phrases represented as numerical vectors. These vectors are used to measure the similarity between words and phrases. (Pinecone. (Extracted 2023) I).
In addition, this vector database uses a variety of distance metrics to measure the similarity between words and phrases. Some of the most common distance metrics that Pinecone uses are: (Pinecone. (Extracted 2023) II).
- Euclidean: This metric measures the distance between two points in a plane. It is one of the most commonly used distance metrics.
- Cosine: This metric is often used to find similarities between different documents. The advantage is that the scores are normalised to the [-1,1] range.
- Dot product: This metric is used to multiply two vectors. It can be used to tell us how similar the two vectors are. The more positive the answer is, the closer the two vectors are in terms of their directions.
Abstractive question answering or Retrieval Augmented Generation (RAG)
Using “out of the box” LLM models for context-depending tasks will result in the model’s poor performance due to these models being “stuck in time” and lacking domain-specific knowledge. A way to tackle this problem is by fine-tuning an existing model, but this can be complicated if you don’t have the computing resources and you don’t have sufficient data. Another way to solve this problem is by implementing Retrieval-Augmented Generation (RAG). (Proser, Z. (Extracted 2023)) & (Riedal, S. et al. (2020)).
RAG is an AI framework for retrieving facts from an external knowledge base, allowing an improvement of the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
RAG consists of two phases: retrieval and content generation. In the first, snippets of relevant information for the user’s prompt are retrieved by search algorithms. After this, an augmented prompt is created by appending the external knowledge to the user’s prompt. In the later generative phase, the augmented prompt is fed into the LLM input, allowing it to synthesise an answer based on the model’s external knowledge and internal representation. This answer can be more engaging to the user and can be exposed, for example, in a chatbot interface. (Martineau, K. (2023)).
Methodology for Abstractive Question-Answering System: Integrating ETL, Pinecone, and Generative Model
In developing our abstractive question-answering system, we have followed a comprehensive methodology that combines data extraction, transformation, and loading (ETL), the efficiency of Pinecone for document retrieval, and the power of generative models to produce coherent abstract answers. Here is a detailed overview of our methodology:
1. ETL Phase: Data Preparation for Efficient Retrieval
The ability to efficiently extract, transform, and load data is essential for natural language processing projects. We will explore the ETL (Extraction, Transformation, and Loading) process behind this project and how to gather relevant information from the web, normalise it, and prepare it for efficient search and retrieval.
1.1 Extraction: Navigating the Web for Relevant Data
The first stage of our journey takes us to data extraction. Using tools like Selenium and Beautiful Soup in Python, we scour the web for information related to our abstractive question-answering system.
We define a primary URL and employ a CSS selector to identify and extract pertinent links. Each link is organised into a list of dictionaries with a unique key and the corresponding URL. We then access each extracted URL and extract the relevant text content using another CSS selector.
The data is stored in a list of dictionaries that includes a unique title and the extracted text from each page.
1.2 Transformation: Preparing Data for Processing
In the transformation phase, we bring the extracted data into a suitable form for further processing, cleaning and normalising the text content to ensure consistency and uniformity. Using custom functions, we create text files (.txt) from the extracted data and organise them in a specific folder. We normalise the text by removing special characters, converting it to lowercase, and eliminating duplicate spaces. Additionally, we use the NFKD technique to normalise accented characters. The normalised data is written to .txt files in a format that facilitates further processing.
1.3 Loading: Preparing Data for Search and Retrieval
The loading phase is critical to convert the normalised text files into actionable documents and prepare the data for search and retrieval. We use the LangChain library to load text documents from the .txt files into a suitable structure for processing. Long documents are split into smaller fragments to facilitate search and processing. Next, we generate embedding vectors for each text fragment using a pre-trained model from Hugging Face. Finally, we created a search index in Pinecone that enables efficient searches based on vector similarity.
2. Retrieving Relevant Documents with Pinecone
Pinecone is the powerhouse for retrieving relevant documents that lay the groundwork for generating precise and abstract answers. We leverage its retrieval capabilities to find documents that closely match the queries, and here’s how it’s implemented:
2.1 Retrieval Mechanism
The heart of our retrieval mechanism lies in a Python function explicitly designed for this purpose. This function bridges user queries and Pinecone’s vector database, ensuring that we retrieve the most contextually relevant documents.
2.2 Querying Pinecone
When a user poses a question, the query is given to Pinecone. The Pinecone index, previously prepared during the loading phase, is now ready to perform efficient searches based on vector similarity. 3
2.3 Retrieval Workflow
Here’s an overview of how the retrieval process unfolds:
- User Query: A user submits a question to our system, seeking an abstract answer.
- Pinecone as a Retriever: We configure Pinecone as a retriever, specifying a search type for similarity matching. This setting ensures that the retrieved documents closely match the query.
- Top-k Retrieval: To offer a comprehensive response, we define the top-k parameter, determining the number of top-relevant documents we aim to retrieve. Pinecone excels in providing accurate results even when dealing with extensive datasets.
- Query Execution: The query is executed in Pinecone, and the retriever swiftly identifies the most contextually similar documents, ensuring high precision.
- Extracting Text Content: Once the most relevant documents are identified, we extract and compile the text content from these documents. These text snippets are invaluable for the subsequent step of generating abstract answers.
3. Abstract Answer Generation: Transforming Retrieved Information into Coherent Responses
From the description of RAG in the critical concepts section, we learned that this process consists of two parts: the retrieval, described in the last paragraph, and the generation. We can use this method to answer the user question with the documents retrieved from the Pinecone database.
In the RAG article published by Meta, they propose using the Bidirectional and Auto-Regressive Transformers (BART) model as the seq2seq generator component of the system. In our case, we use the Llama-2-chat model, which is a fine-tuned version of the model that is optimised for dialogue and comes in a range of parameter sizes (7B, 13B, and 70B).
Llama2 can be loaded via Hugging Face (which requires authentication and verifying Meta granted access to the models) or by using the llama.cpp chain from LangChain.
Either way, these models are too big to be used only with CPU, and to use, for example, Google Colab, you must use quantisation to fit the model into the free tier GPU (T4 GPU). As a solution for this, we found that Fireworks AI contains all the different versions of Llama2, and in the free plan, it allows us to make 10 requests/min, which was perfect for our prototype development. (Briggs, J.(2023)) ,(fireworks.ai. (Extracted 2023)) & (LangChain. (Extracted 2023).
Also, as we already explained, Fireworks API can be used with the LangChain API, as it will be described in the next section.
3.1. LangChain LLM chain
One of the chains that LangChain offers is the LLMchain. An LLMChain is a simple chain that adds some functionality around language models. It is used widely throughout LangChain, including in other chains and agents.
An LLMChain consists of a PromptTemplate and a language model (either an LLM or chat model). It formats the prompt template using the input key values provided (and memory key values, if available), passes the formatted string to LLM and returns the LLM output.
Calling the chain would look like:
“llm_chain = LLMChain(prompt=prompt_template, llm=gen_model)“
Note: The prompt template is the one we’ll explain in the following section, and the gen model is the model loaded from Fireworks ai.
3.2. Langchain prompts
Langchain contains a class called PromptTemplate, which, as its name states, is a prompt template for a language model. It consists of a string template that accepts a set of parameters from the user that can be used to generate a prompt for a language model. The template can be formatted using f-strings (default) or jinja2 syntax.
Llama2 can receive a prompt where you can specify the behaviour of the model and an instruction for the model like summarise, answer or another task. The format of this prompt will be:
“[INST]<<SYS>>\n System prompt \n<</SYS>>\n\n Instruction [/INST]”
Taking advantage of the f-strings capability inside the LangChain prompts, the context will be inserted in the system prompt and the query will be inserted in the instruction, that way, generating our prompt will look like
“prompt_template=PromptTemplate(template, input_variables= [‘context’, ‘question‘]“
With the system prompt and the instruction, the generated prompt would look like:
“[INST]<<SYS>>\n You are a helpful assistant that works at the company \”Equinox AI Lab\”, a company specialised in Artificial Intelligence, Data Science and Design. \n You can use this information as help to answer but answer as if you already know it: {context} \n<</SYS>>\n\n Please provide an answer to the following question based on the context you know: {question} [/INST]”,
3.3. Fireworks.ai Llama2 model
Fireworks.ai supports all versions of the Llama2 model, so we use the biggest chat variant model, the llama-v2-70b-chat. To load it into our app, we need the model name and input some arguments for the model, like the number of tokens to generate or the temperature (to avoid hallucinations from the model; this is a number close or equal to 0).
“gen_model=Fireworks(model=model_name, model_kwargs={“temperature”:temperature}“
Workflow
Based on the methodology we have applied, our abstractive question-answering system is divided into three distinct phases:
- First Phase: Building the Knowledge Base
In this initial stage, we extract relevant information from documents stored in Langchain. Using the documents as outlined in our methodology, we pass them through a specialised model to generate embeddings. These embeddings are then stored in a vector database managed by Pinecone.
- Second Phase: Information Retrieval
When a user enters a question into the system, the second phase comes into play. Through a retrieval function, we conduct a similarity-based search within our Pinecone vector database. Allowing us to identify the most relevant documents in response to the user’s query.
- Third Phase: System Response Generation
Finally, in the third phase, the system takes the retrieved documents and the user’s provided question. Subsequently, this information is fed into our language generation model. The model leverages these data to generate an eloquent and appropriate response presented to the user.
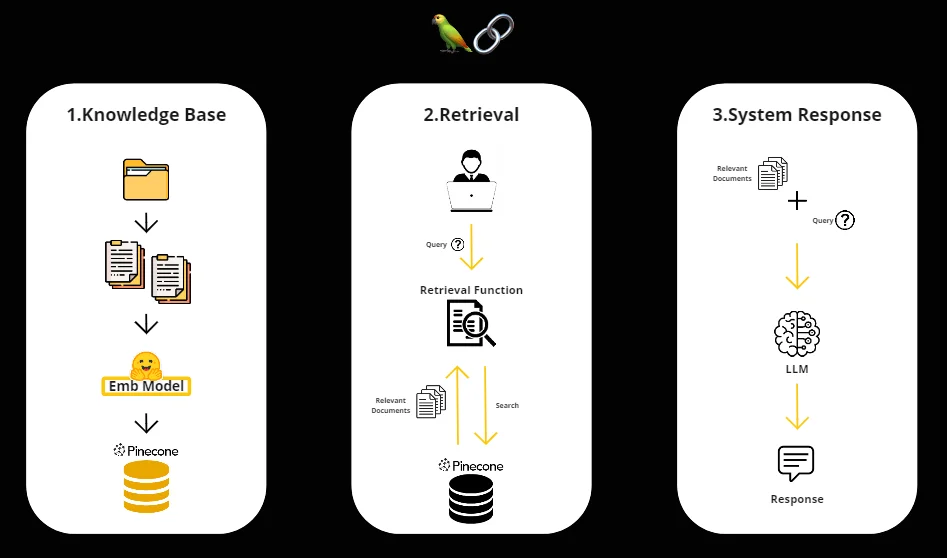
Image2: Workflow
Results (MVP)
Following the previously mentioned workflow, we implemented a prototype of an application that provides answers to questions in an abstractive way. This application was deployed using Streamlit to assess the results achieved through our applied methodology.
Once our knowledge base was prepared, users could input questions into the system. Additionally, we provided the flexibility to adjust various hyperparameters:
- Top_k: This controls the number of context passages provided to the large language model for answer generation. In other words, it determines how many documents we want to retrieve from our information retrieval system.
- Temperature: Users could select a value for this hyperparameter, influencing response generation. A lower value ensures more coherent and context-aligned responses, while a higher value produces more diverse responses.
- LLM Model: Users had the option to choose the generative language model to be used for generating responses to their questions. We used the model “llama-v2” trained with 70 billion parameters in this case.
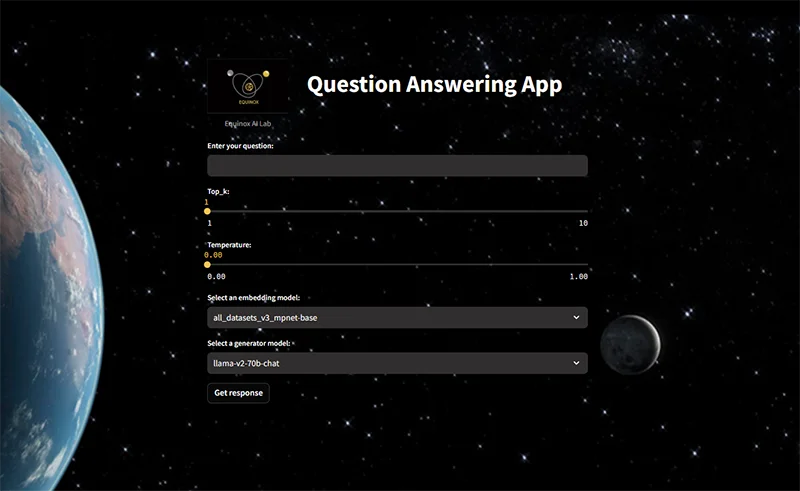
Image3: MVP
This prototype allows users to experiment and evaluate the system’s performance, as well as customise their preferences to obtain answers that better suit their needs.
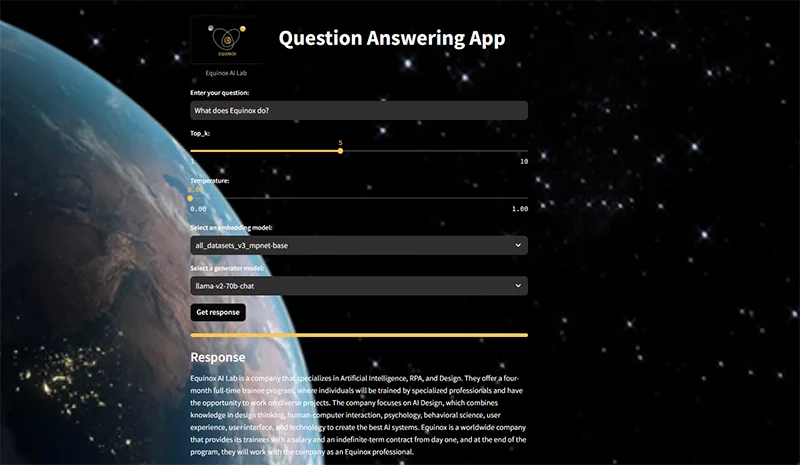
Image4: MVP Results
CONCLUSION
In conclusion, the methodology and workflow for building an abstractive question-answering system demonstrate a well-structured and efficient approach to the development of advanced AI-powered systems. The combination of ETL processes for data preparation, Pinecone for precise information retrieval, and generative language models for eloquent responses offers a holistic solution for addressing complex user queries.
It is crucial to note that for the system to perform optimally, one must carefully evaluate the various methods of document retrieval to ensure the highest level of accuracy and relevance in responses. As we look to the future, further research and development in this field should focus on enhancing these retrieval techniques, expanding the system’s knowledge base, and continuously fine-tuning generative models for even more contextually aware and precise answers. The adaptability of this approach makes it applicable across various domains and industries, further underlining its versatility and immense potential impact.
References
Karpathy, A. (2023) State of GPT. https://karpathy.ai/stateofgpt.pdf
Microsoft Developer (Producer) Karpathy, A. (Speaker). (2023). https://www.youtube.com/watch?v=bZQun8Y4L2A
LangChain Blog. (2023). Bringing Free OSS Models to the Playground with Fireworks AI. https://blog.langchain.dev/bringing-free-oss-models-to-the-playground-with-fireworks-ai/#:~:text=Fireworks.ai%20provides%20a%20platform,foundation%20models%20for%20fine%2Dtuning
LangChain. (Extracted 2023). Introduction. https://python.langchain.com/docs/get_started/introduction
Hugging Face. (2022). Getting Started With Embeddings. https://huggingface.co/blog/getting-started-with-embeddings
Pinecone. (Extracted 2023). Overview. https://docs.pinecone.io/docs/overview
Pinecone. (Extracted 2023). Understanding indexes. https://docs.pinecone.io/docs/indexes
Proser, Z. (Extracted 2023). Retrieval Augmented Generation (RAG): Reducing Hallucinations in GenAI Applications. https://www.pinecone.io/learn/retrieval-augmented-generation/
Riedal, S. et al. (2020). Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models. https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
Martineau, K. (2023). What is retrieval-augmented generation? https://research.ibm.com/blog/retrieval-augmented-generation-RAG
Briggs, J. (Producer & Director). (2023). Better Llama 2 with Retrieval Augmented Generation (RAG). https://www.youtube.com/watch?v=ypzmPwLH_Q4
fireworks.ai. (Extracted 2023). Pricing. https://readme.fireworks.ai/page/pricing
LangChain. (Extracted 2023). Llama.cpp. https://python.langchain.com/docs/integrations/llms/llamacpp

Laura Mantilla – Data Engineer

Santiago Ferreira – Data Scientist
EQUINOX
what’s ai?
Discover what is AI and how it will become revolutonary in the industry
