¿Cómo se ve el futuro de la interacción humano-máquina?
Últimamente, la gran pregunta que nos reta todos los días es: ¿cómo podemos hacer que nuestros productos tecnológicos simplifiquen cada vez más la vida de las personas y suplan las limitaciones de la tecnología actual? La idea de llegar a una experiencia agradable y que impacte positivamente a los usuarios desvela tanto a pequeños empresarios como a las grandes multinacionales.
Con el objetivo de empezar a soñar experiencias nuevas, más allá del monitor, el teclado y el ratón; primero, debemos revisar cuál ha sido la historia de la relación humano-máquina para luego – sobre experiencias aprendidas – podamos contemplar las relaciones usuario-interfaz del futuro.
Según lo anterior, este artículo tiene como objetivo hacer un recuento histórico de lo que ha sido tal relación para luego proponer posibles vías de innovación en lo que refiere a este campo, tales como Interfaces invisibles.
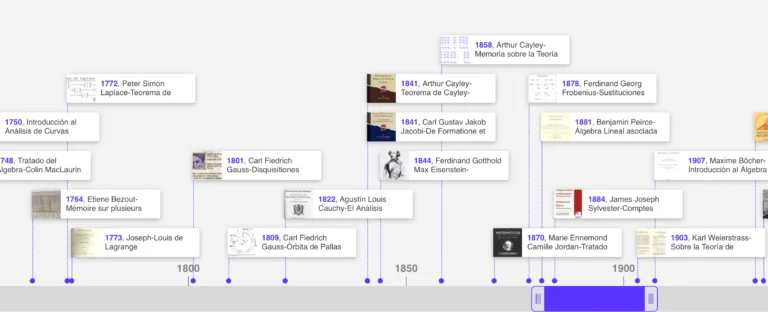
Un recorrido por la historia de la relación humano-máquina

Fotografía por Gilles Lambert en Unsplash
La relación entre los seres humanos y las máquinas (acotando la definición de este concepto a la tecnología computacional) data desde 1980, tras la primera ola de computadores personales y de escritorio. Si bien previamente ya existían las interfaces de líneas de comando (CLIs), no fue hasta que las primeras computadoras invadieron los hogares y oficinas que el público general tuvo la posibilidad de interactuar con estos sistemas electrónicos. A partir de ese momento, se democratizó el uso de estas máquinas por medio de las interfaces gráficas de usuario (GUI) y su metáfora del “escritorio”.
Entre 1990 y principios de los 2000, las personas empezaron a utilizar los computadores como medio de comunicación para socializar con los demás, colaborando y difundiendo conocimiento a través del correo electrónico. A esta nueva experiencia se sumaron las mejoras en la sensibilidad de los ratones al tacto y la presión. No obstante, las innovaciones en las GUIs no fueron demasiadas, manteniendo los conceptos de ventanas y archivos junto con el gesto de “arrastrar y soltar” del cursor.
Durante los siguientes 10 años, los usuarios empezaron a interactuar con el contenido digital de manera revolucionaria gracias a las pantallas táctiles y el infinito universo de las aplicaciones. Estas innovaciones permitieron que la tecnología tomara un rol más amplio en la vida de las personas. Por ejemplo, se empezó a usar como una , un medio de autoexpresión y una herramienta de apoyo en procesos de crecimiento personal, moldeando sus hábitos y protagonizando la paradoja de “estar solos pero acompañados”.
Desde entonces, las interfaces táctiles han permeado todos los aspectos de la vida humana. Sin embargo, en el 2011 surge un nuevo tipo de interacciones humano-máquina. Por un lado, están las asistentes de voz y las interfaces conversacionales, las cuales han ganado popularidad gracias a su interacción natural a partir del lenguaje humano. Por otro lado, existen las experiencias inmersivas que le agregan una nueva dimensión a las interfaces al utilizar la totalidad del campo visual humano; y los ambientes inteligentes (AmI), que toman los avances de la IA, la computación ubicua y los sensores sin contacto para crear espacios físicos sensibles y responsivos.
¿Cuál es el futuro de las interfaces? La necesidad de una nueva generación de interacciones más humanas

Al mirar hacia atrás, nos damos cuenta que – durante los últimos 30 años – la relación humano-máquina se ha basado principalmente en interacciones generadas a partir de teclados, ratones y paneles táctiles. Sin embargo, estos periféricos no han logrado cerrar la brecha entre las capacidades computacionales y el comportamiento humano. Por ejemplo, estos siguen presentando inconvenientes al resultar inaccesibles para minorías como los adultos mayores (quienes encuentran las pantallas complejas y ambiguas) y las personas con habilidades especiales (que se frustran tras no poder interactuar del todo). Sin tener que ir más lejos, que estas interfaces involucren mayoritariamente el sentido de la vista, hace que al menos 2200 millones de usuarios que sufren de deficiencia visual se vean perjudicados.
A pesar de que las últimas tendencias en tecnología – mencionadas anteriormente – eliminan las barreras físicas y se acercan más a la naturaleza humana, estas sólo corresponden al comienzo de una nueva generación de interfaces. Entonces, ¿cómo sería una relación entre las personas y las máquinas en la que estas últimas entiendan e interpreten los comportamientos humanos físicos y mentales? ¿Qué pasaría si las interfaces permiten una experiencia a partir de los 5 sentidos, percibiendo nuestro cuerpo en el espacio e incluyendo funcionalidades gestuales?
Definitivamente, el siguiente camino de la innovación en interfaces debe salirse de los límites de las pantallas bidimensionales de vidrio, a las que nos hemos acostumbrado. Los nuevos avances tecnológicos deben permitir interacciones más cercanas a la biología humana, favoreciendo que la ejecución de cualquier tarea sea aún más intuitiva y ampliando el espectro de experiencias.
Ahora bien, antes de empezar a imaginarnos un mundo en el que reinen las PVUIs (Projected Visual User Interfaces) o en el que toda solución se inspire en los principios de diseño del HUD (Head-Up Display), considero que se ha de reflexionar acerca de las posibles características que deben tener las relaciones humano-máquina del futuro. Al tomar las propuestas por la startup alemana Senic, a continuación menciono las más relevantes, en mi opinión:
- Descentralizadas, interfaces invisibles y mágicas.
Las interacciones se alejarán de las GUI y pasarán a ser omnipresentes, estando siempre donde se las necesite. Éstas harán parte de nuestro entorno, en las paredes o ventanas de la casa u oficina, y darán lugar a escenarios en los que podamos hacer un gesto en el aire para prender la luz de una habitación. Incluso, serán capaces de leer nuestras emociones y entender lo que estamos haciendo para anticipar nuestras necesidades. Esta idea resulta valiosa al permitir que las personas no tengan que sostener una pantalla o bajar la mirada para verla, concentrándose en situaciones más importantes.
- Específicas.
Esta es la premisa más beneficiosa y retadora de todas. Pasar de pensar en soluciones que todo el mundo pueda utilizar, como en su momento lo diseñó Steve Jobs, y empezar a ofrecer experiencias únicas para situaciones concretas. Ejemplo de esto sería diseñar interfaces que brinden interacciones hápticas especiales para personas con profesiones en la industria creativa, o que apliquen métodos de aprendizaje basados en la gamificación para niños.
- Centradas en los humanos.
Este concepto recalca la necesidad de incursionar con máquinas que perciban, entiendan y procesen tanto el cuerpo como la mente humana desde sus diferentes aproximaciones. Así, esto nos lleva a imaginarnos sistemas que detecten movimientos cerebrales y que entreguen información desde los múltiples sentidos.
- Instantáneas.
Aquí, nos cuestionamos si se puede realizar una tarea sin necesidad de pasar por varios pasos, ni siquiera dos o tres. Resolver las actividades humanas al instante y reducir la carga cognitiva de las personas resultará en una mejor y menos estresante experiencia para el usuario.
CONCLUSIÓN
Mejorar la experiencia de los usuarios se trata de un trabajo continuo. Siempre habrá más por aprender acerca de las diversas maneras en las que, como seres humanos, nos relacionamos con la tecnología. Las situaciones actuales nos dan la oportunidad de ser creativos y entregar valor al crear experiencias que no se limiten a las superficies de interacción existentes. Se ha de seguir aprovechando y potenciando las posibilidades que nos aporta la Inteligencia Artificial, con sus capacidades de procesamiento de lenguaje natural (NLP) y el Computer Vision, o los beneficios que trae consigo la realidad virtual y aumentada. No obstante, se ha de ir aún más lejos y crear experiencias que verdaderamente simplifiquen la vida de todos sin excepción.
REFERENCIAS
AltexSoft Inc. (2018, 1 julio). Principles of Interaction Design: What It Takes to Create Positive Human-Computer Interactions. Medium. UX Planet. https://bit.ly/3aHjQLF
Asher, M. (2017, 18 julio). The History Of User Interfaces—And Where They Are Heading. Adobe. https://adobe.ly/3tYVHrq
Campbell, C. (2021, 22 enero). Ambient Intelligence — The Invisible Interface. Medium. Start It Up. https://bit.ly/3sUS9VR
Ekenstam, L. (2015, 25 octubre). Magic Leap — The next big frontier in human+computer revolution. Medium. https://bit.ly/2PqWp1R
Kim, A. (2018, 11 julio). What is Human Computer Interaction (HCI)? Medium. https://bit.ly/2R4DzxG
La OMS presenta el primer Informe mundial sobre la visión. (2019, 8 octubre). Organización mundial de la Salud. https://bit.ly/3gMDyJX
Senic. (2015, 8 enero). The Future of Human Computer Interaction. Medium. https://bit.ly/3gH7Eyc
Usabilla. (2017, 15 mayo). A Short History of Computer User Interface Design. Medium. The UX Blog. https://bit.ly/3nmT9Bb
What is Human-Computer Interaction (HCI)? (2021). The Interaction Design Foundation. https://bit.ly/2R1To8o
Xiao, L. (2017, 17 julio). A Brief History of Human-Computer Interaction (HCI). Medium. Prototypr.io. https://bit.ly/3vgHsyo

Sara Feijoo – AI Designer

VISIT OUR KNOWLEDGE CENTER
We believe in democratized knowledge
Understanding for everyone: Infographics, blogs, and articles
Let’s tackle your business difficulties with technology
” There’s a big difference between impossible and hard to imagine. The first is about it; the second is about you “

Marvin Minsky, Professor pioneer in Artificial Intelligence












{kind=link}
{kind=link}
{kind=link}
{kind=link}