Author: Juan Sebastian Casas – Data Scientist
MOTIVATION
Deaf and hard-of-hearing people face significant barriers to communication due to their lack of hearing. Breaking communication barriers with AI (and Visión por computadora) can be a game-changer for this community. These barriers can limit their ability to fully participate in society, as they are often excluded from verbal communication and rely heavily on sign language and other forms of communication.
In addition, the lack of accessibility and awareness about the needs of people with this disability can further hinder their integration and full participation in daily life in educational, work, and social environments.
INTRODUCTION
The creation of a sign language-to-audio translator could have a significant impact on the lives of people with hearing disabilities. The development of this technology could enable better communication, leading to greater independence and connection to the world around them. For example, they might more easily participate in meetings, classes, and social events where oral language is predominantly used.
One of the technological solutions to this problem is la inteligencia artificial, which, thanks to its significant advances in visión por computadora and deep learning, can recognise gestures and patterns without needing external wearables. This means that the AI can analyse large amounts of sign language data and autonomously learn to identify and classify the most common gestures and patterns. And combining this AI model with speech processing technologies, it is possible to create a real-time sign language-to-audio translation system.
STATE OF THE ART
At present, there are different systems and technologies dedicated to the translation of sign language to audio. Some of these use signal processing, pattern recognition, and machine learning techniques to interpret hand and body movements and gestures in sign language and transform them into sounds and spoken words. Among the most common methods used in these systems are the use of cameras and motion sensors to capture the user’s gestures and the use of image processing and pattern recognition algorithms to interpret them. Even though these systems still have certain limitations, such as the difficulty in recognising more complex gestures or the need for precise calibration, their ability to facilitate communication between deaf and hearing people is increasing.
One of the clearest examples of the use of machine learning to make this translation is the company SignAll, which uses a combination of cameras and motion sensors to interpret sign language, capturing the movement of the body, the shape of the hands, and facial movement, to translate it into text and voice in real-time. [1]
Another example can be found with the MotionSavvy UNI product, which uses a Leap Motion optical controller to capture the movement of the hands. This device was combined with a tablet to perform sign language to audio translation.[2]
Finally, the company SignAloud developed a pair of gloves that use position and motion sensors to detect the movements of the user’s hands and then translate them into spoken words and phrases. The system uses advanced sequential statistical regression technology to analyse the data and thus perform the translation. [3]
EXPERIMENTATION
For a first iteration of a computer vision sign language-to-audio translator, there are several ways to go. The first is to start training a convolutional neural network from scratch. This includes getting all the data needed for training, iterating over various architectures, hyperparameter tuning, and more. Another path that can be chosen is to transfer learning from an already pre-trained neural network that has been trained in a similar task, such as image classification. This option allows you to take advantage of prior knowledge of the neural network and tailor it for the specific task of the sign language to an audio translator.
The technique used for this first iteration was transfer learning; it has some advantages compared to training from scratch [4].
Some of these are:
- Fewer data needed: pre-trained models have already learned valuable features on large and diverse data sets. Hence, they need fewer data to train and generally produce more accurate results than models trained from scratch.
- Faster training speed: Training from scratch requires more time and computational resources than transfer learning since all model parameters are initialised randomly.
- Improves generalisation: pre-trained models have learned to extract useful features in different types of images and can, therefore, better generalise across various computer vision tasks.
A. DATA
A dataset of sign language gestures is required to develop the sign language-to-audio translator. However, it is not necessary to use a vast number of images for the training cause we’re not trying to learn the features that the pre-trained model already knows. We want to focus on capturing the nuances and intricacies of sign language gestures specific to this task. This means that a smaller, curated dataset of sign language gestures, with precise labelling and annotation, can be sufficient for the model’s training.
For the first iteration of the training, a dataset of 15 images per phrase was created for five different phrases: ‘I love you’, ‘Yes’, ‘No’, ‘Thank you’, and ‘Hello’. Resulting in just 75 images for the whole project.
As seen in Image 1, the sign language gesture used to train the model is the “Hello” sign. This gesture was captured using a phone camera and passed to a computer to continue with the labelling part.

Image 1. Sign language “Hello.”
B. LABELS
Continuing the training, it is necessary to assign labels to each image in the dataset. In this case, the label correspond to the sign language gesture being performed in each frame. To generate these labels, a manual labelling process was performed using LabelImg, which is a popular image annotation tool. For each image, a label was assigned to represent the sign gesture being performed, and a bounding box was created to identify the hands in the image (object detection). This process ensures that the model can accurately identify and classify the sign gestures in new images it encounters during use.
An example of the labelling process using LabelImg can be seen in Image 2. In this example, the image shows a person performing the sign gesture for “I Love You.” The LabelImg tool drew a bounding box around the hands in the image, representing the sign gesture. The label “I Love You” was then assigned to the image. This process was repeated for all images in the dataset, ensuring each image was accurately labelled and annotated for the sign gesture. The labelled dataset was then used to train the sign language-to-audio translator to accurately classify and translate sign gestures in real time. [5]
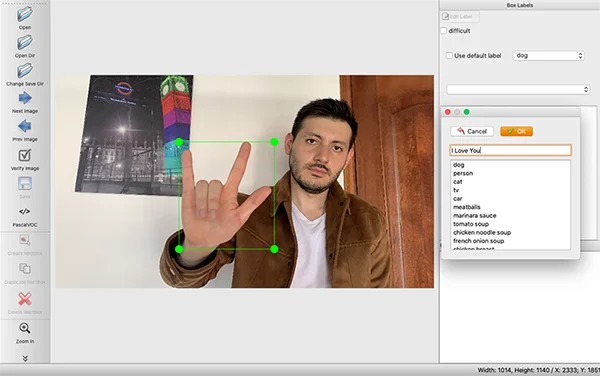
Image 2. Labelled image “I Love You”
C. TRAINING
The dataset was used to fine-tune a pre-trained object detection model using transfer learning. The chosen pre-trained model was the SSD MobileNet V2 FPNLite 640×640 architecture, which was trained on the COCO17 dataset. The last layer of the model was replaced with a fully connected layer with five output neurons corresponding to the sign language gestures. The new layer was fine-tuned using the sign language dataset for 10,000 training steps with a batch size of 4. [6]
This is an object detection model using the Single Shot Multibox Detection (SSD) framework. [7] It is designed to identify and locate objects of five different classes in an image, which are the sign language gestures for “I love you”, “Yes”, “No”, “Thank you”, and “Hello”. The input image is resized to 640×640 pixels before processing. The optimiser used is a momentum optimiser with a cosine decay learning rate. Data augmentation was not used, as the pre-trained model came with its data augmentation techniques, including random horizontal flips and random crops.
D. RESULTS
The fine-tuned SSD MobileNet V2 FPNLite 640×640 model achieved a DetectionBoxes_Precision/mAP score of 0.81, indicating good performance in identifying and localising sign language gestures for “I love you”, “Yes”, “No”, “Thank you”, and “Hello”. In addition, the total loss at the end of the 10,000 training steps was 0.16 (in graph 1), showing that the model could effectively minimise its loss function during training.
Overall, these results demonstrate the effectiveness of transfer learning and the suitability of the SSD MobileNet V2 FPNLite 640×640 architecture for object detection tasks. The results also suggest that the model has the potential to be applied in real-world scenarios where accurate and efficient sign language recognition is needed.
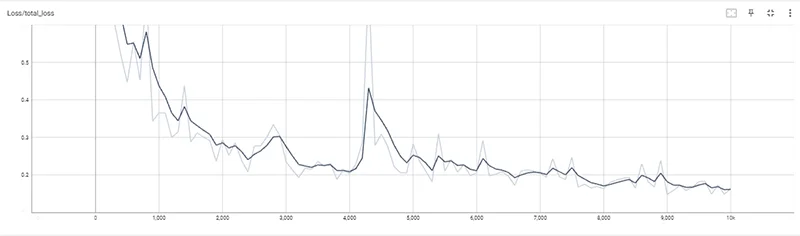
Graph 1. Total_loss
AUDIO
With the object detection model trained, we can now focus on implementing the audio translation component of the system. One approach would be to use the output of the object detection model to determine which sign language gestures were made and use a text-to-speech library to generate spoken output in the desired language. This process could be implemented using various Python libraries such as TensorFlow and PyTorch for the object detection model and libraries like gTTS for text-to-speech.
WHAT’S NEXT?
To further improve the accuracy of the sign language recognition project, a possible next step would be first to train a model specifically to recognise hands. This specialised model could then be fine-tuned and trained with sign language gestures, potentially resulting in a more precise and reliable system. By breaking down the task into smaller, more focused components, the model could better differentiate between the different elements of sign language, such as hand shapes, movements, and facial expressions, leading to improved recognition and interpretation.
Another essential aspect to consider for the future of this project is the expansion of the training data. While the current dataset of static images provides a good foundation for the model, there are many sign language phrases that use movement gestures. To improve the accuracy of the model, it would be helpful to incorporate videos of sign language phrases into the training data. Additionally, the model would benefit from a more extensive vocabulary of sign language phrases, allowing it to understand better and interpret more complex messages. By expanding the training data and vocabulary, we can continue to improve the accuracy and usability of the model for individuals who use sign language.
CONCLUSION
In conclusion, the development of a sign language-to-audio translator using artificial intelligence technology could greatly benefit individuals with hearing disabilities by enabling better communication and facilitating their integration into society. While there are currently several technologies available for translating sign language to audio, there is still room for improvement, particularly in terms of recognising more complex gestures and enhancing the overall accuracy of the translation. By using techniques such as transfer learning and smaller, curated datasets with precise labelling, it is possible to train AI models to better recognise and interpret sign language gestures in real time. Further research and development in this field could significantly improve the accessibility and inclusion of individuals with hearing disabilities.
REFERENCIAS
- (n.d.). SignAll Lab. SignAll Lab. https://www.signall.us/lab
- Strauss, K. (2014, October 27). MotionSavvy UNI: 1st sign language to voice system. Forbes. https://www.forbes.com/sites/karstenstrauss/2014/10/27/tech-tackles-sign-language-motionsavvy/?sh=a3bc60478627
- https://medium.com/biofile-programa-de-historias-cl%C3%ADnicas-en-la-nube/signaloud-guantes-que-traducen-el-lenguaje-de-se%C3%B1as-a-voz-y-texto-2352d15deff0
- S. (2014, October 27). Benefits of Transfer Learning. Kaggle. https://www.kaggle.com/general/291011
- Sell, L. (2022, September 22). LabelImg – README. Github. https://github.com/heartexlabs/labelImg.
- Ssd_mobilenet_v2/fpnlite_640x640. Tfhub. https://tfhub.dev/tensorflow/ssd_mobilenet_v2/fpnlite_640x640/1
- Hui, J. (2018, March 13). SSD object detection: Single Shot MultiBox Detector for real-time processing. Medium. https://jonathan-hui.medium.com/ssd-object-detection-single-shot-multibox-detector-for-real-time-processing-9bd8deac0e06.

Juan Sebastian Casas – Data Scientist
