
Author: Laura Mantilla – Data Engineer
SUMMARY
This article explores how insurance companies in Colombia can leverage Artificial Intelligence (AI) and Machine Learning (ML) to detect and prevent fraud in insurance claims. Given the growing economic impact of fraud in the sector, the most effective techniques for identifying suspicious patterns and improving detection accuracy are analyzed. Additionally, the article provides a methodological approach for applying these techniques in the insurance industry, highlighting how effective implementation can optimize fraud detection and offer sustainable long-term benefits.
Keywords: Artificial Intelligence, Machine Learning, Predictive Models, Classification Algorithms, Fraud Detection.
INTRODUCTION
Insurance fraud is a growing and concerning issue in Colombia, affecting not only the finances of insurance companies but also policyholders and the economy in general. According to data collected by the Colombian Federation of Insurers (Fasecolda), in the second half of 2021, 9,916 fraud cases were detected, totaling more than 67.95 billion pesos (approximately 16.8 million dollars), with insurers disbursing 8% of that amount. These frauds mainly impacted SOAT (Mandatory Traffic Accident Insurance), Occupational Risks, Health, and Automobile insurance (Fasecolda, 2022).
However, the situation has intensified in recent years. In 2023, the number of detected frauds exceeded 24,300 cases, a significant increase compared to 2021. Of these cases, 62% were related to SOAT, which continues to be the most affected area. Economically, these frauds represented around 242 billion pesos (approximately 59.98 million dollars), of which insurers paid about 12%, approximately 30 billion pesos, with the regions of Bogotá, Antioquia, Valle del Cauca, and Atlántico being the most impacted (El Tiempo, 2024).
This increase in both the number of cases and the economic impact highlights the urgent need to adopt more effective methods for the prevention and early detection of fraudulent claims. This article explores how Artificial Intelligence (AI) and Machine Learning (ML) techniques can be key tools in this effort, proposing approaches to optimize fraud identification before payments are made, thus protecting the interests of both insurers and policyholders.
Classification Methods for the Detection of Fraudulent Claims
In the field of fraud detection, classification methods play a crucial role in helping to identify patterns that indicate fraudulent activities. These methods are applied through two main phases: model training and testing.
First, the model is trained using historical data with claims labelled as fraudulent or non-fraudulent to learn to identify patterns. Then, its performance is evaluated with a new dataset to verify its ability to correctly classify previously unseen claims.
Figure 1. Logic of a Predictive Model.
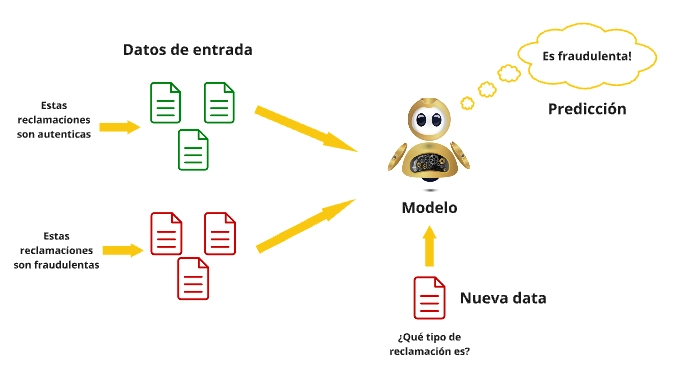
Created by the author
The following explores the basic concepts of some of these methods and their application in the identification of fraud in insurance data:
LOGISTIC REGRESSION
Logistic Regression estimates the probability that a claim is fraudulent using a logistic function, which converts predictions into probabilities between 0 and 1. In the context of fraud detection, this method helps predict whether a claim is fraudulent based on key characteristics. It is useful when the data show a clear linear separation between fraud and non-fraud. However, it may have limitations if the data does not fit a linear model well.
DECISION TREES
The Decision Tree organises decisions in a tree structure. Each node represents a decision based on a characteristic, such as the amount of a claim, and the branches show the possible outcomes. To detect fraud, the tree classifies claims by dividing them according to criteria such as whether the amount is high or low. This methodology helps to identify patterns and provides an intuitive way to classify claims as fraudulent or non-fraudulent.
RANDOM FORESTS
The Random Forest uses multiple decision trees to improve classification accuracy. Each tree is trained on a different part of the dataset, and their results are combined to obtain a final prediction. This method is effective in detecting complex patterns and reducing the risk of overfitting, which is crucial in datasets where fraudulent claims are much less common than legitimate ones.
Figura 2. Random Forest structure
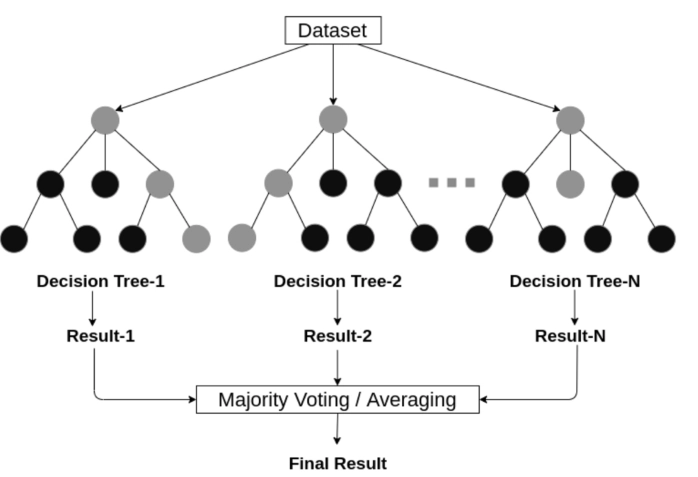
Taken from (Sarker, I. H.,2021)
(KNN)
K-Nearest Neighbours (KNN) ranks a claim based on similarity to the nearest claims in the dataset. The algorithm identifies the k nearest neighbours of a new claim and uses majority voting to determine its ranking. For example, if the majority of the k nearest neighbours are fraudulent, the claim will also be classified as fraudulent.
In fraud detection, KNN is useful when the data has complex and non-linear patterns. However, its accuracy depends on the quality of the dataset and the appropriate choice of the number of K neighbours.
Implementation and Training of Classification Algorithms
Effective implementation of classification algorithms for insurance fraud detection requires a structured approach that encompasses several key stages. We will build on the stages proposed in the methodology of (Ismail, A., 2022) which include:
Table 1. Phases for the implementation of ML algorithms.
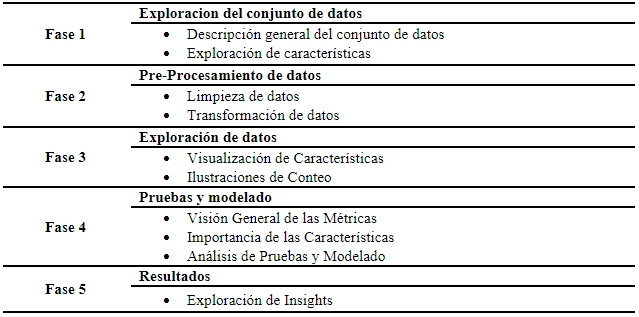
Adapted from (Ismail, A., 2022)
Phase 1: Exploring the dataset
This stage is key to understanding what information we have and how it is presented. This helps us to understand the quality of the data and to identify potential problems early on. To approach this phase effectively, it is important to consider the following premises: overview of the dataset, exploration of characteristics and identification of potential problems.
In (Ismail, A., 2022) the study was conducted with a dataset taken from Kaggle, which was collected by Angoss Knowledge Seeker software between January 1994 and December 1996. This dataset consists of 15,420 insurance claims records and 33 features, such as:
Figure 3. Features in the dataset.

Taken from (Ismail, A., 2022)
In exploring the dataset they found that, of the 33 characteristics, 9 were numerical variables and the remaining 24 categorical. In addition, the dataset had no null values for any of the features.
Figure 4. Information from the dataset.

Taken from (Ismail, A., 2022)
Phase 2: Data pre-processing
Data pre-processing is crucial to ensure the quality and effectiveness of predictive models used in fraud detection. This process includes data cleaning to correct errors and remove duplicates, imputation of missing values to maintain the consistency of the dataset, and removal of irrelevant information to focus the analysis on the most relevant variables to identify fraud.
In the study of (Ismail, A., 2022), as shown in Figure 4, the dataset has no missing values. The main challenge in the preprocessing was the conversion of categorical variables to numerical variables, an essential step for machine learning algorithms to properly process and analyse the information and thus improve the detection of fraudulent activities.
Figura 5. Raw data set.
Taken from (Ismail, A., 2022)
Figure 6. Processed data set.
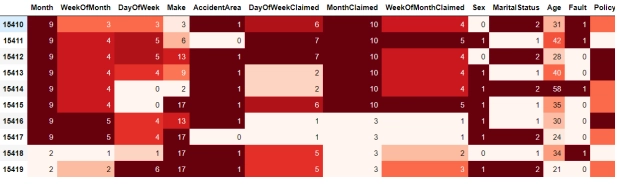
Taken from (Ismail, A., 2022)
Phase 3: Data exploration
Once the data has been pre-processed, data exploration focuses on more detailed analysis. This phase uses various techniques and tools to visualise and analyse the data, allowing for the identification of more subtle patterns and relationships between variables.
According to (Komorowski et al., 2016), Exploratory Data Analysis (EDA) has several key objectives: understanding the structure of the data, visualising relationships between variables, finding outliers and anomalies, and extracting important variables. For fraud detection, these practices are essential to uncover subtle patterns and anomalies in claims.
Table 2. Recommended EDA techniques depending on the type of data.

Adapted from (Komorowski et al., 2016)
Exploratory analysis of the dataset taken from (Ismail, A., 2022) reveals several important findings on fraudulent claims:
Seasonality in Fraudulent Claims: The months of March, May and January are observed to have a higher probability of fraudulent claims, possibly due to seasonal factors and a higher volume of claims in these periods.
Figure 7. Probability of fraudulent claims by month.
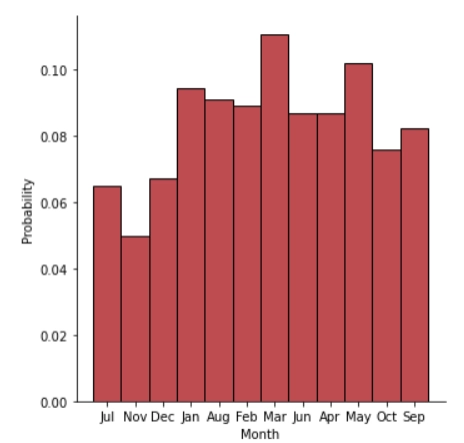
Taken from (Ismail, A., 2022)
Fraudulent Activity by Day of the Week: Monday and Friday, the days with the highest number of complaints, also show a higher percentage of fraud (see Figure 8). This could indicate that the increase in the number of complaints facilitates the commission of fraud.
Figure 8. Fraudulent activity on days of the week.
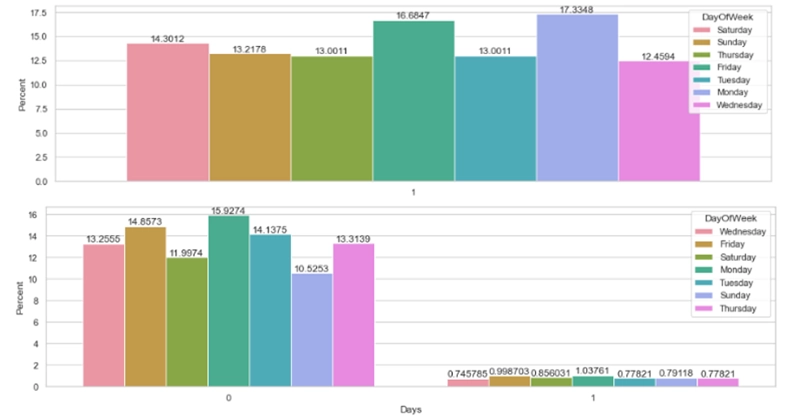
Taken from (Ismail, A., 2022)
Vehicle Type and Fraud: Sedans are the vehicles most commonly associated with fraudulent claims (5.15%), compared to utility vehicles (0.2%) and sports cars (0.5%) (see Figure 9). This finding may be useful for adjusting predictive models.
Figure 9. Percentage of fraud by vehicle type.

Taken from (Ismail, A., 2022)
In addition to the observed patterns, a problem of class imbalance within the dataset was identified. With 94% of claims being non-fraudulent and only 6% fraudulent, there is a significant skew in the distribution of classes.
This imbalance can affect the accuracy of the classification model, as most algorithms tend to be biased towards the majority class. It is therefore crucial to address this imbalance, possibly using adjustment techniques such as oversampling or undersampling to improve the model’s ability to detect fraud.
The oversampling technique consists of increasing the number of examples of the minority class (fraudulent claims) by replicating existing cases or generating new synthetic examples. This balances the proportion between the classes in the dataset and helps the model to pay more attention to the minority class, thus improving fraud detection by reducing the bias towards the majority class.
Figure 10. Oversampling technique.
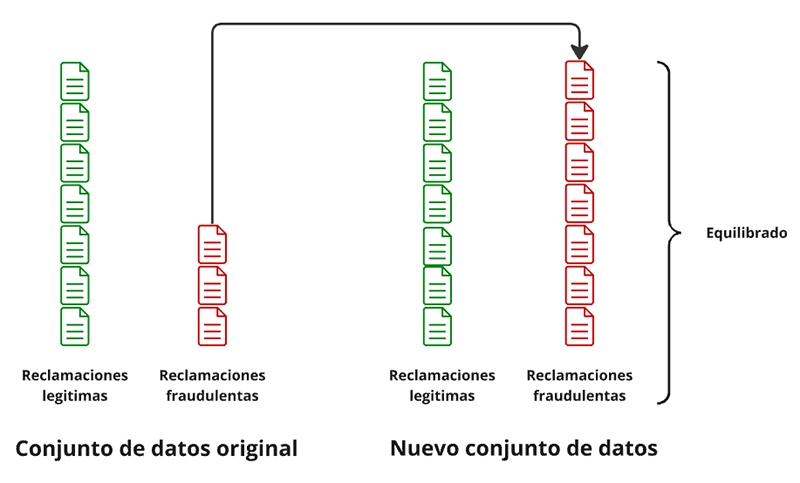
Created by the author
On the other hand, the undersampling technique involves reducing the number of examples from the majority class (legitimate claims) to balance the proportion between classes in the dataset. By decreasing the number of cases from the majority class, the balance with the minority class (fraudulent claims) is improved, which helps to avoid bias towards the majority class and facilitates better fraud detection.
Figure 11. Sub-sampling technique.
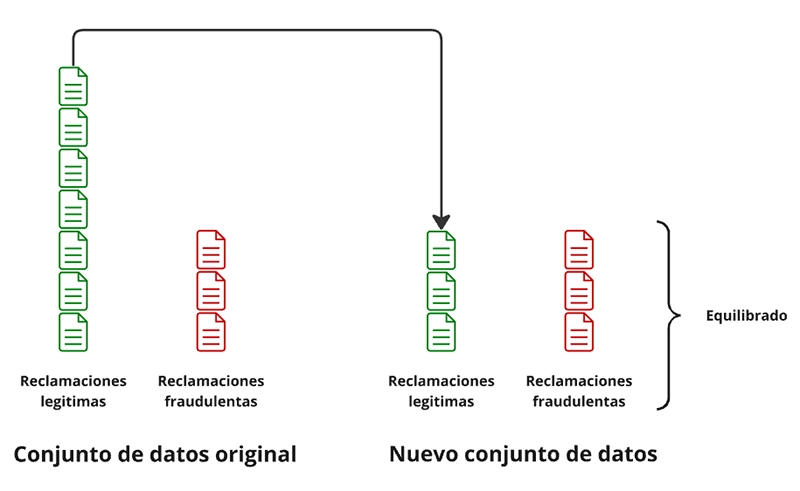
Created by the author
Phase 4: Testing and modelling
Once we have identified patterns in the data and tuned the dataset, the next step is to build and train a model to detect fraud. Here are the key steps to build and train a machine learning model, following the principles of (Ismail, A., 2022):
- Model Building: Based on the prepared data, selecting the appropriate algorithm for the problem. Here models are created and trained according to the previously identified patterns and features.
- Evaluation and Validation: Dividing the data set into training and testing parts to validate model performance. Using techniques such as cross-validation to ensure that the model generalises well to new data and not just the training data.
- Model Optimisation: Adjusting model parameters to improve model accuracy and performance. This may include fine tuning techniques and selection of relevant features.
- Model Deployment: Once the model has been optimised, it is deployed to detect fraud in real time or on new data sets.
It is important to mention that there are several metrics to assess the accuracy and effectiveness of a model. According to (Hossin, M., & Sulaiman, M. N., 2015), these metrics provide a comprehensive view of model performance from different perspectives:
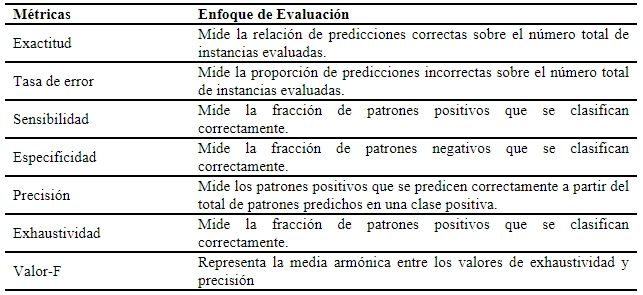
Adapted from (Hossin, M., & Sulaiman, M. N., 2015)
Phase 5: Results
Finally, the analysis of results is carried out, this includes the exploration of the insights obtained to interpret the findings and validate the proposed solution, ensuring that the model is not only effective in theory, but also meets the requirements and expectations in real situations.
In the following, we will analyse the results obtained in (Ismail, A., 2022) during the evaluation of the Logistic Regression, KNN, Random Forest and XGBoost models:
Table 4. Comparison of performance metrics

Adapted from (Hossin, M., & Sulaiman, M. N., 2015)
The results in Table 4 show that Random Forest and KNN are the best performing models in accuracy, precision, sensitivity and F1 score. Random Forest achieves the best accuracy (0.98) and high precision and sensitivity (0.98), while KNN also shows outstanding performance with an accuracy of 0.96 and similar metrics in precision and sensitivity.
Logistic Regression, on the other hand, underperforms with an accuracy of 0.75, and lower precision, sensitivity and F1 metrics compared to the other models. This indicates that Logistic Regression may not be the most appropriate choice for this particular problem, given the overall poor performance.
For fraud detection, the choice of the right metric is crucial due to the imbalance in the dataset. In this case, where only 6% of claims are fraudulent, the model needs to be sensitive to detecting these rare cases to be effective. In this context:
Accuracy measures the proportion of true positives among all positive predictions made by the model. Although important, high accuracy does not guarantee that the model will detect all fraud cases, especially if the model is biased towards the majority class.
Recovery measures the proportion of true positives correctly detected among all true positives. In fraud detection, high recovery is crucial because we want to ensure that we identify as many fraudulent claims as possible.
F1 Score is the harmonic mean between accuracy and sensitivity, providing a balance between the two. This metric is particularly useful in unbalanced datasets such as ours, as it combines the ability to detect (recovery) with the accuracy of positive predictions (precision).
Given the imbalance in the dataset, with a majority of non-fraudulent cases, recall is the most relevant metric to assess the model’s performance in fraud detection. We want to minimise the number of false negatives (fraudulent cases that are not detected), which is reflected in high recall.
CONCLUSIONES
This article highlights how Artificial Intelligence (AI) and Machine Learning (ML) can be very effective tools for detecting insurance claims fraud in Colombia. Among the models evaluated by (Ismail, A., 2022), the Random Forest and the KNN have proven to be the most effective. The Random Forest, in particular, achieved the highest accuracy (0.98) and showed excellent precision and sensitivity. The KNN also performed very robustly. In comparison, Logistic Regression was not as successful, suggesting that it is not the best choice for this type of problem.
Furthermore, it is crucial to address the imbalance in the dataset, given that most claims are legitimate and only a small fraction are fraudulent. Techniques such as oversampling and undersampling can help improve fraud detection by balancing class representation and preventing the model from biasing towards the majority class.
In our case, where effective fraud detection is a priority without compromising the quality of legitimate data, oversampling seems to be the most appropriate technique. By increasing the representation of fraudulent claims, this technique allows the model to better focus on identifying these rare cases without losing valuable information from legitimate claims.
These findings show that, in addition to properly choosing and fitting models, it is also crucial to manage data imbalance to optimise fraud detection. Implementing these techniques and methods can help insurers improve the identification of fraudulent claims, thereby reducing risks and associated costs.
REFERENCIAS
Fasecolda. (2022, 30 de marzo). La industria aseguradora detectó fraudes por más de $68 mil millones [Comunicado de prensa]. https://www.fasecolda.com/cms/wp-content/uploads/2023/06/La-industria-aseguradora-detecto-fraudes-por-mas-de-68-mil-millones-.pdf
El Tiempo. (2024, 6 de febrero). SOAT encabeza escalafón de pólizas con las que más se comete fraude en Colombia. El Tiempo. https://www.eltiempo.com/economia/sector-financiero/fraudes-esta-es-la-poliza-con-la-que-mas-estafan-a-las-aseguradoras-852030
Sarker, I. H. (2021). Machine learning: Algorithms, real-world applications and research directions. SN Computer Science, 2, 160. https://doi.org/10.1007/s42979-021-00592-x
Ismail, A. (2022). Fraudulent Insurance Claims Detection Using Machine Learning. Thesis. Rochester Institute of Technology. https://repository.rit.edu/cgi/viewcontent.cgi?article=12510&context=theses
Komorowski, M., Marshall, D., Salciccioli, J., & Crutain, Y. (2016). Exploratory Data Analysis. https://www.researchgate.net/publication/308007227_Exploratory_Data_Analysis.
Hossin, M., & Sulaiman, M. N. (2015). A Review on Evaluation Metrics for Data Classification Evaluations. International Journal of Data Mining & Knowledge Management Process, 5(2), 01-11. https://www.researchgate.net/publication/275224157_A_Review_on_Evaluation_Metrics_for_Data_Classification_Evaluations

Laura Mantilla – Data Engineer