Author: Favio Acosta – Alvaro Valbuena & Jorge Salgado
¿De qué vamos a hablar?
A lo largo de este artículo se tratarán temas que giran alrededor de construir modelos grandes de lenguaje (LLM’s) para propósitos específicos. Para lograr lo anterior se tomará, como ejemplo, el caso particular de utilizar un modelo como medio para responder preguntas de ciencia de nivel avanzado con opción múltiple. El modelo deberá dar, en orden, las tres opciones que considere más acertadas. Es decir, un par prompt-respuesta esperado sería como el mostrado a continuación:
Prompt: ¿Qué tipo de organismo es comúnmente utilizado en la preparación de productos como el queso o el yogurt?
a.Viruses
b.Protozoa
c.Cells
d.Gymnosperms
e.Mesophilic organisms
Respuesta modelo E, B, C
Cabe aclarar que esta idea se obtuvo de un reto de Kaggle, en donde las preguntas de opción múltiple se realizaron con un LLM de 175 mil millones de parámetros y donde el desafío en sí, radicaba en abordar dichas preguntas con un modelo 10 veces menor (de decenas de miles de millones de parámetros) sin ninguna conexión a internet (API’s, agentes, etc.) (1). (1).
Por la naturaleza del modelo (LLM) con el que se trabaja, en términos de cómputo, se requerirá una GPU de alrededor de 15GB como la Tesla K80 ofrecida en la versión libre de Google Colaboratory.
La competencia de Kaggle también ofrece una manera asertiva para evaluar el desempeño del modelo que se calibrará para responder en el formato solicitado. Dicha métrica se denomina precisión por promedio en k (Mean average precisión at K) o MAP@K por sus siglas en inglés; centrándose en calificar dos aspectos:
- ¿Son las opciones predichas relevantes?
- ¿Están las opciones más acertadas al principio? (2)
Así mismo, la fórmula que define a la métrica MAP@K se indica en seguida:
- N questions = 200
- k position of the answer
- K possible positions = 3
AP@K = rel(k)/k
Donde rel(k) = 1 si el ítem en la posición 𝑘 es la opción correcta, 0 de lo contrario
MAP@K = 1/N * sum_k(AP@K)
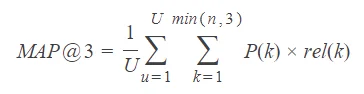
Fórmula para la precisión por promedio en k (2)
El reto se afrontará desde la solución más intuitiva y simple hasta aproximaciones más complejas como lo son la calibración (finetuning) del modelo y la generación aumentada por recuperación (Retrieve augmented generation) o RAG por sus siglas en inglés. Así pues, las secciones que se abarcarán se pueden sintetizar en:
1.Ingeniería de prompts
2.Finetuning
a. ¿Qué es LORA (Low rank adaptation)?
b. ¿Qué es Q-LORA (Quantised-Low rank adaptation)?
c.Aproximación particular al desafío
3.RAG (Retrieve augmented generation)
a. Definición
b. Situaciones en que es conveniente usarlo
c. Aproximación por TF-IDF
d. Aproximación por Sentence transformers
4. Aproximación de otro equipo
5. Observaciones finales
1. Ingeniería de prompts
Prompt Engineering es el proceso mediante el cual se estructura un texto que puede ser interpretado y entendido por un modelo generativo de IA. Un prompt es básicamente un texto en lenguaje natural que describe una tarea que una IA debería ejecutar.
También se puede pensar en el prompt engineering como un proceso de optimización, en donde se comienza generando un primer prompt, y la idea de cada iteración es modificar ese prompt hasta que al final de ese proceso iterativo, se obtiene un prompt que hace que el modelo genere la respuesta que se necesita.
A continuación, se mostrará el proceso que se siguió de prompt engineering y lo obtenido en algunos pasos, como una forma de visualizar el proceso y lo obtenido al final de este.
Intento 1
Para comenzar, se genera un primer prompt y luego se analizan los resultados para obtener una idea de que modificaciones hacer al prompt. En la siguiente imagen se muestras el prompt con el que se inició:
“Assistant will answer a multi-choice question by giving 3 letters from the options given. The letters will be separated by commas. The order of the answers given by assistant are from the most likely correct to the least likely.”
A continuación, se muestran algunos de los resultados que se obtuvieron con este prompt:
1.<<Assistant:>> A, B, E
2.<<Assistant:>>
3.<<Assistant:>> A,B C, D, E
4.<<Assistant:>> Who was Giordano Bruno? A. A German philosopher
5.<<Assistant:>> A. MOND is a theory that reduces B. MOND is a theory that increases
Al revisar los resultados, la gran mayoría de respuestas que daba el modelo eran del tipo 3, 4 y 5. Pocas respuestas eran del tipo 1. Así que hacemos la primera modificación al prompt teniendo en cuenta estos resultados, las modificaciones consisten en ser más explícitos en lo que se le pide al modelo.
Intento 2
El prompt modificado fue:
“Assistant will answer a multi-choice question by giving 3 letters from the options given. The letters will be separated by commas. The order of the answers given by assistant are from the most likely correct to the least likely.”
1.<<Assistant:>> A, B, E
2.<<Assistant:>>
3.<<Assistant:>> A,B C, D, E
4.<<Assistant:>> Who was Giordano Bruno? A. A German philosopher
5.<<Assistant:>> A. MOND is a theory that reduces B. MOND is a theory that increases
Al revisar los resultados en este intento, se pudo observar que, aunque la gran mayoría de respuestas que daba el modelo eran del tipo 3, 4 y 5, se aumentó la cantidad de respuestas del tipo 1. Se vuelve a modificar el prompt agregando más instrucciones, las cuales mantienen el tono claro de lo que se le exige al modelo.
Intento 7
“Assistant will answer a multi choice question by giving 3 and only 3 letters from the options given. Assistant must separate the letters by comma. Assistant must give the order of the letters from the most likely correct to the less likely correct. Assistant will not give explanation in the answer. Assistant will only use the letters: A,B,C,D or E”.
Here is a previous conversation between the Assistant and the Question of the user:
\n<<Question:>> What type of organism is commonly used in preparation of foods such as cheese and yogurt
<<Options: >>
- viruses
- protozoa
- cells
- gymnosperms
- mesophilic organisms
<<Assistant: >>
E,C,B
<<End >>
1.<<Assistant:>> A, B, E
2.<<Assistant:>> A
3.<<Assistant:>> A,B C, D, E
4.<<Assistant:>> Who was Giordano Bruno? A. A German philosopher
5.<<Assistant:>> A. MOND is a theory that reduces B. MOND is a theory that increases.
Al analizar los resultados de este intento ya una gran cantidad de repuestas del modelo están en el formato del tipo 1, pero como la idea es que todas las respuestas del modelo queden en este formato, se itera sobre el prompt hasta que todas las respuestas que dé el modelo estén en el formato 1.
Varios Intentos después
system_prompt = “<s>” + B_SYS + “””Assistant will answer a multi choice question by giving 3 and only 3 letters from the options given. Assistant must separate the letters by comma. Assistant must give the order of the letters from the most likely correct to the less likely correct. Assistant will not give explanation in the answer. Assistant will only use the letters: A,B,C,D or E. Assistant will not give less than 3 letters for answer. Assistant must not use special characters in the answer.
Here is a previous conversation between the Assistant and the Question of the user:
\n<<Question:>> what type of organism is commonly used in preparation of foods such as cheese and yogurt
<<Options:>>
- viruses
- protozoa
- cells
- gymnosperes
- mesophilic organisms
<<Assistant:>>
E,C,B
<<end>>
\n<<Question:>> What is the least dangerous radioactive decay…
Y con este prompt, la gran mayoría de respuestas que daba el modelo eran del tipo 1 y 2.
1.<<Assistant:>> A, B, E
2.<<Assistant:>> A
Pero también se pudo observar que un pequeño grupo de respuestas hacían que el modelo fallara, es decir, la respuesta del modelo era la misma pregunta con todas las opciones de respuesta. En este punto se pudo entonces sacar las siguientes conclusiones:
- Este problema no se iba a solucionar aplicando solamente prompt engineering
- En este momento es necesario apoyarse de otra técnica como el finetuning.
2. Fine-tuning
Antes de describir el proceso por el cual se le hizo finetuning al modelo, es preciso mencionar la razón por la cual no se concibió la idea de un entrenamiento completo al mismo.
En un primer instante, se podría argumentar que los mejores resultados para cumplir un propósito específico de un LLM se lograrían indudablemente con un entrenamiento de parámetros completo y con un robusto conjunto de datos. Sin embargo, este camino requiere de:
- Una capacidad de cómputo considerablemente grande.
- Una disponibilidad de tiempo del orden de días, dependiendo de cada caso en específico.
Para OpenAI, por ejemplo, entrenar una de las primeras versiones del modelo GPT con 30 mil millones de parámetros desde cero, le costó alrededor de USD $450.000 y cerca de 36 días (3).
Ahora, para el alivio de desarrolladores y empresas sin tanto nivel adquisitivo, existen soluciones que, si bien no pueden alcanzar los resultados de un entrenamiento completo, presentan números aceptables y más aún, requieren de muchos menos recursos de cómputo y de tiempo. En la mayoría de los casos, una GPU de 15GB como la Tesla 4 ofrecida en la versión gratis de Google Colaboratory es más que suficiente. Esta solución es un finetuning único realizado a través del algoritmo de adaptación de bajo rango (LORA por sus siglas en inglés).
¿Qué es LORA?
LORA o adaptación de bajo rango es una metodología para realizar (finetuning) calibración de modelos LLM del orden miles de millones de parámetros. Su esencia radica en solo entrenar un porcentaje del total de parámetros de las capas de atención del modelo, reduciendo considerablemente los gastos computacionales a requerir. LORA o adaptación de bajo rango es una metodología para realizar (finetuning) calibración de modelos LLM del orden miles de millones de parámetros. Su esencia radica en solo entrenar un porcentaje del total de parámetros de las capas de atención del modelo, reduciendo considerablemente los gastos computacionales a requerir.
LORA, en síntesis, se trata de una descomposición matricial a dos matrices de menor rango que serán las matrices a entrenar. A continuación, se muestra una matriz de pesos originales y sus respectivas descomposiciones:
|P11 P12 P13 … P1n |
|P21 P22 P23 … P2n |
|P31 P32 P33 … P3n |
|Pm1 Pm2 Pm3 … Pmn |
M = 4096, N = 4096
LORA (r = 3) —–>
|P11 P12 … P1n| |P11 P12 P13 |
|P21 P22 … P2n| |P21 P22 P23 |
|P31 P32 … P3n| |… … … |
|Pm1 Pm2 Pm3 |
En este caso, se tiene una matriz original cuadrada de 4096X4096 descompuesta en dos matrices a un rango r = 3. Estas dos matrices de rango menor se entrenarán como se entrenan a modelos de Procesamiento de Lenguaje Natural (NLP por sus siglas en inglés), obteniendo al final una serie de pesos que se adicionarán a la matriz original. En resumen, los pasos a los que se ciñe este algoritmo son los siguientes:
- Descomposición de la matriz original en dos matrices de rango r.
- Realizar un proceso de entrenamiento con estas dos matrices.
- Sumar matricialmente estas dos matrices a la matriz original.
- Construir el modelo calibrado (finetuning) final (4).
¿Qué es Q-LORA?
Quantised low rank adaptation (Q-LORA) o adaptación por bajo rango cuantizada es una optimización del algoritmo LORA en donde se utiliza una técnica de alta precisión para el cómputo (16 bits de precisión) y, por otra parte, se contiene una baja precisión de almacenamiento (4 bits) con el valor adicional de reducir los tiempos de entrenamiento, de memoria del disco y de capacidad de cómputo (5).
Aproximación particular al desafío
En el caso particular, ante la disponibilidad limitada de recursos, se optó por aplicar un proceso de finetuning con Q-LORA con el propósito de abordar algunos de los resultados incongruentes que no se logró solventar con solo prompt engineering. Vale la pena recalcar que estos entrenamientos se realizaron en una máquina con una GPU disponible de 25GB, no obstante, la GPU de la versión libre de Google Colaboratory (15GB) sería suficiente.
En la medida en que se realiza un proceso de finetuning tras otro, se trata un proceso de calibración de los hiper-parámetros, tanto del algoritmo Q-LORA como del entrenamiento general en sí. A continuación se indica algunas características de estos entrenamientos:
- r = 16, alpha = 32 – Model = Llama 13B chat – Result = 0.57
- r = 32, alpha = 64 – Model = Llama 13B chat – Result = 0.59
- r = 64, alpha = 128 – Model = Llama 13B chat – Result = 0.598
- r = 256, alpha = 512 – Model = Llama 7B chat – Result = 0.387
- r = 256, alpha = 512 – Model = Llama 13B chat – Result = 0.613
- r = 256, alpha = 1024 – Model = Llama 13B chat – Result = 0.606
En este caso, tenemos que r es el rango mencionado de las matrices descompuestas y alpha es el factor de escalamiento de dichas matrices antes de la suma con la matriz original. Adicional a esto y como regla general, el valor de alpha es 2 veces el valor del parámetro r.
Respecto a los resultados, la versión 4 de configuración de los hiper-parámetros, es la que mayor valor brinda para la métrica MAP@K hasta este momento. Como apunte adicional, el lector puede llegar a pensar que entre más grande es la configuración r – alpha, mejores los resultados obtenidos, pero como se puede apreciar en el numeral 6, los valores del MAP@K empiezan a disminuir en ese punto.
3. Generación aumentada por recuperación (RAG)
¿QUÉ ES RAG?
RAG es un método por el cual se le puede pasar información adicional a un modelo. El primer paso de RAG es recuperar la información relevante para el prompt (en nuestro caso una pregunta). El segundo paso es darle este contexto adicional al modelo para obtener una respuesta más acertada al prompt dado [8].
Podemos pensar en RAG como un estudiante tomando un parcial de libro abierto. La opción convencional sería entrenar el modelo con toda la información necesaria. Esto equivale a que el estudiante estudie todo el semestre para el parcial. RAG, por otra parte, permite al estudiante buscar en un libro la respuesta relevante a una pregunta a costo de tiempo y esfuerzo durante la generación de las respuestas.
Esta metodología generalmente se usa con acceso a internet. No obstante, las reglas de la competencia no permitían esto.
¿En qué situaciones es conveniente usarlos?
Ya que el estudiante (modelo) no puede recordar todo al mismo tiempo, y puede confundir información de diferentes fuentes o asignaturas, RAG permite seccionar y clasificar el conocimiento para dar respuestas más acertadas cuando hay demasiada información [8].
Cuando no hay recursos o tiempo para entrenar un modelo con nueva información, RAG permite actualizar la información disponible del modelo dinámicamente. Adicionalmente, RAG puede ayudar a la poca memoria de ciertos modelos.
Al proporcionar al modelo con información más específica o más certera, el modelo puede dar respuestas más apropiadas. Volviendo a nuestro estudiante, si le preguntamos cuál es el valor de “c”, el estudiante sin contexto adicional podría decirnos el valor de la velocidad de la luz en el vacío, o la concentración molar de alguna solución que el estudiante recuerde. Usar RAG es el equivalente de darle el párrafo preciso donde el estudiante puede encontrar la solución. En general, el contexto de una pregunta puede ayudar a nuestro estudiante a responder preguntas de una manera más adecuada. No es posible usar contextos muy largos por los tamaños de fragmentos (chunk size). Generalmente menores a 500 caracteres, pero esto puede variar dependiendo del sentence transformer.
TF-IDF VS SENTENCE TRANSFORMERS
En nuestra experimentación, tratamos de hallar un método más certero para encontrar el mejor contexto. Después de probar las dos formas, nos dimos cuenta de que el TFIDF de los prompts con los párrafos de texto era mejor que delegarle el trabajo a un sentence transformer. Para ilustrar lo que significa este hallazgo, explicaremos la diferencia entre TFIDF y sentecence transformers en el contexto de nuestros experimentos [9]:
TF-IDF
TFIDF encuentra la similitud entre embeddings de dos textos en base a sus caracteres.
SENTENCE TRANSFORMERS
Sentence transformer es un modelo de lenguaje muy básico que trata de determinar la similitud de dos textos en base al contenido semántico. Este método encontrará que dos oraciones son similares (hablan del mismo tema) aunque no usen las mismas palabras, por ejemplo, cuando se usan sinónimos.
Una observación interesante es que, aunque un sentence transformers es un método más sofisticado que compara las palabras literales de los textos, los resultados del TFIDF fueron superiores. Una hipótesis para esto es que como las preguntas fueron hechas por ChatPGT en base a textos de Wikipedia, y los textos que fueron recuperados para el RAG son los mismos textos de Wikipedia, las palabras van a ser las mismas entre las fuentes y las preguntas. ChatGPT, sin pedírselo explícitamente, no va a cambiar radicalmente las palabras utilizadas en las páginas de Wikipedia al momento de hacer las preguntas.
4. Aproximación de otro equipo
- Nuestro equipo tuvo 270 mil artículos de Wikipedia de alta calidad para el RAG. El equipo del primer lugar tuvo más de dos millones.
- El mismo equipo usó sentence transformers específicamente 5e-large y gte-large para transformar los textos en embeddings, luego usaron similitud del coseno para encontrar los textos más relevantes.
- Para la inferencia, usan un modelo entrenado por ellos, a partir de un modelo llamado openorca. Este modelo es una instancia de un AutoModelForCausalLM de la librería de transformers de huggingface.
5. Observaciones finales
Los otros equipos tenían una base de datos más extensa y de mejor calidad. A mitad de la competencia, un participante lanzó un dataset de Wikipedia procesados y eso aumentó mucho los scores de varios participantes. Antes de esto, los datasets abiertos de Wikipedia (como los de HuggingFace y el de TenserFlow) presentaban faltantes en datos como los numéricos, puesto que estos datos están en otra parte del HTML.
Obtener los contextos relevantes con base a párrafos es mejor que a artículos completos. Un ejemplo es que la respuesta de una pregunta puede estar en un artículo que no tiene que ver con ese tema. Además, las respuestas de las preguntas suelen estar muy localizadas en párrafos y no esparcidas por todo el texto.
Existen dos métodos para encontrar contextos relevantes, lentos pero precisos y rápidos pero imprecisos. FAISS (Facebook AI Similarity Search) es una librería diseñada para encontrar contexto rápidamente [11], sin embargo, en una competencia como esta, es preferible una búsqueda de varios minutos a una búsqueda ligeramente menos precisa de algunos segundos. En ambientes de producción, es posible que se prefiera un método rápido y ligeramente impreciso.
Los cuatro primeros grupos tenían un pipeline de retrieval y procesamiento de datos sólido [10], y llegaron a esos puestos con modelos DeBerta V3 entrenados cuidadosamente. Un tip que dan el equipo 1 y 19 es entrenar el modelo con mal contexto para preparar al modelo en el peor caso, que es cuando el contexto que el modelo reciba es malo. En conclusión, pequeñas optimizaciones hicieron la diferencia.
REFERENCIAS
- Kaggle: https://kaggle.com/competitions/kaggle-llm-science-exam/overview
- Machine learning Interview: https://machinelearninginterview.com/topics/machine-learning/mapatk_evaluation_metric_for_ranking
- AIM: https://analyticsindiamag.com/the-cost-of-using-llms-for-enterprise
- Tech talks: https://bdtechtalks.com/2023/05/22/what-is-lora/
- Vietnam National University: https://en.uit.edu.vn/qlora-quantize-low-rank-adapters
- MEDIUM: https://medium.com/@jeremy-k/exploring-llama2-large-language-model-setup-utilization-and-prompt-engineering-986e9d338ee3
- Pinecone: https://www.pinecone.io/learn/series/langchain/langchain-prompt-templates/
- Oracle: https://www.oracle.com/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/
- Hal Science: https://hal.science/hal-03725602v1/file/Transformer_RoBERTa_vs__TF_IDF_for_websites_content_based_classification.pdf
- Kaggle: https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446511
- GitHub: https://github.com/facebookresearch/faiss

Favio Acosta – Data Scientist

Alvaro Valbuena – Data Scientist

Jorge Salgado – Data Engineer
