
This article NLP: The magic behind understanding machines, talks about Natural Language Processing or NLP, a branch of knowledge between Artificial Intelligence and Linguistics that aims to give machines the ability to understand the language of humans.
NLP involves the analysis of the following:
- Syntax: identifying the syntactic role of each word within a sentence.
Example: in the sentence “I will buy a candy”, “I” is the subject, “candy” is the direct object and “I will buy” is the verb.
- Semantics: determining the meaning of words or phrases.
Example: in the sentence “The engineer went to the customer’s office”, the customer’s office refers to a place.
- Pragmatics: establish how the communicative context affects the meaning.
Example: in the sentence, “David drank wine at the party. It was red.” Red refers to the wine David drank.
We perform these three analyses every day, some almost unconsciously. For us, deriving meaning from language turns out to be very simple and is the consequence not only of a process of development and learning but of thousands of years of evolution. Now, think how difficult it can be for a machine which only understands ones and zeros to understand your emotions when writing a review of a movie or a product you have purchased.
Among the most difficult challenges in NLP are dealing with ambiguous expressions, pragmatics and the implicit use of prior knowledge. Some sentences that show this kind of problem are:
– I will be on the beach with Mary reading. Are you reading, are you both reading or is she reading? (Ambiguity).
– We saw John walking. Did you see that John was walking, or did you see John when you were walking? (Ambiguity)
– The first sprint of the project took one month. The term sprint is technical language in project development (Prior knowledge).
Think how difficult it is for a machine to derive meaning from such sentences if we cannot derive meaning clearly.
WHY IS IT VALUABLE TO HAVE UNDERSTANDING MACHINES?
Language is the primary way for humans to communicate effectively. Think that you use the language daily to perform tasks, make analyses, convey emotions and perform many other actions and needs of your life. Now think, what would happen if a machine that can perform tasks and activities thousands of times faster than you, could understand you, and not only you but thousands of people at the same time.
It is clear that the implications of a machine that understands natural language are fascinating. Here I will present some applications and systems that make use of NLP.
DIALOG SYSTEMS
These systems are divided into two main groups: task-oriented systems and chatbots. The former focus on accomplishing valuable tasks, while the latter focus on maintaining a conversation with the user without implementing any specific task.
The following image shows how these types of systems are divided according to whether they can perform practical tasks and maintain a complex social conversation.
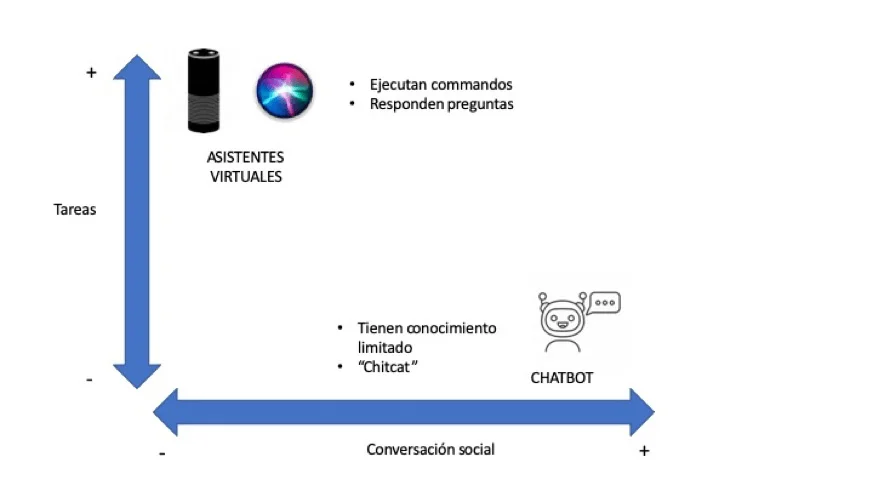
In many business environments, these terms are often confused as all companies ask to develop chatbots when they really want a task-oriented system.
Examples of task-oriented systems are virtual assistants such as Siri, Alexa and Cortana. Chatbots, on the other hand, are characterised by having defined personalities, carrying on entire conversations, and expressing emotions such as fear, temper, and distrust. The trend is to move toward virtual assistants with characters who can handle more complex social conversations yet are knowledgeable on many topics and can perform functional tasks.
TEXT CLASSIFICATION
This is the process of assigning categories to texts according to their content. Four of the most common applications of text classification are:
– Sentiment analysis: when you want to determine whether a text is negative, positive or neutral, or when you want to determine the predominant emotion in a text. This is widely used to analyse texts in social networks or product and service reviews.
– Classification of texts by topic: the objective is to understand what a given text is talking about or its main subject.
– Language detection: you want to determine a given text’s language.
– Intention detection: it is widely used in customer service to classify customer responses according to their intention (interested, not interested, unsubscribe, potential buyer…).
INFORMATION EXTRACTION
This is the process of transforming unstructured information into structured data. The objective is to find important entities within a text (people, organisations, locations, etc.), discover their relationships, and store them in a data structure such as a relational database. The purpose of this is to structure the information so that better analysis can be performed, information can be reused, and better insights can be generated.
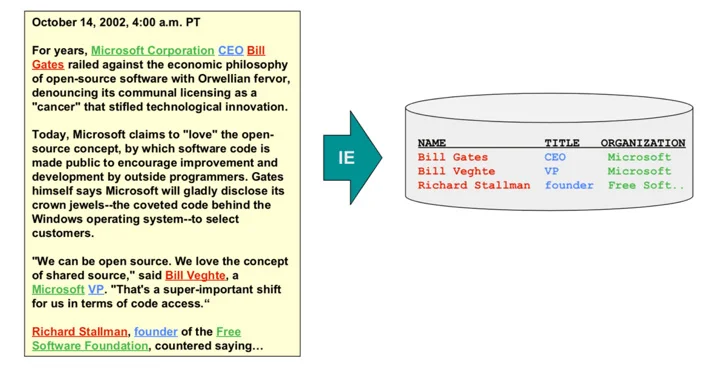
Information Retrieval Systems
Information Retrieval is the science behind search engines. It aims to bring users relevant information from unstructured sources such as text, images, videos and audio. The quintessential example of this type of system is the Google search engine. However, consider all the benefits your company could have if it had an “internal Google” that could bring relevant information to expose all documents, reports, emails and even social networks, according to search criteria that can be written as you normally as you express yourself.
WHERE’S THE “MAGIC” BEHIND IT?
All these NLP systems and applications are based on Machine Learning methods that seem, at first glance, very sophisticated. But how intelligent are these systems? To answer this question, you must first understand what is behind these systems. In general, there is no convention or a defined process to attack this type of project; however, here, I will state three tasks that are usually fundamental in many NLP applications.
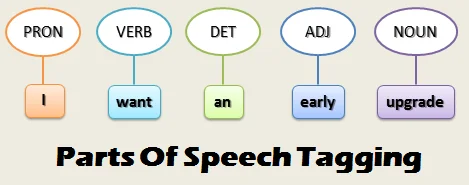
The first one is to do POS Tagging (Part of Speech Tagging), which aims to assign a tag to each word in a sentence according to its syntactic role.
The second is to perform Dependency Parsing, which aims to analyse the grammatical structure of a sentence by establishing relationships between words.
The third is to perform Named Entity Recognition, which aims to find all relevant entities within a sentence. These entities can be people, organisations or places.
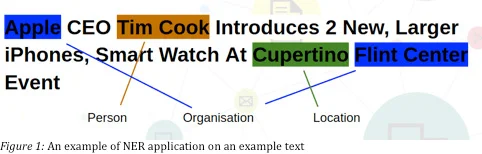
HOW ARE THESE TASKS PERFORMED?
These three tasks are performed automatically by Machine Learning models. It seems almost “magic” that we only have to pass plain text to these models so that they automatically perform these analyses, and we have the labels word by word. However, the reality is that these models are not so magical. All these Machine Learning models are supervised learning, meaning they learn based on many examples we humans must give them. The following example shows how a human must tag the syntactic role of each word (POS tag) in a sentence to provide the machine with an example of how it is done (the tags are in red, and each tag has a meaning):
The/DT grand/JJ jury/NN commented/VBD on/IN a/DT number/NN of/IN other/JJ topics/NNS ./.
Note that there is a tag even for the period!
This is a terribly tedious process. Now note that the example is only one sentence. For such models to automatically perform these tasks, the machines must learn from millions of sentences that a poor human must manually tag. Still, sounds very sophisticated?
There are already vast amounts of tagged documents freely available; however, the differences in the quality of tagging documents, the number of tagged documents and the variability of type of tagged documents between English and Spanish is abysmal, which makes Machine Learning models that automatically perform these tasks mentioned above much better in English than in Spanish or other langauges.
The truth is that, despite these limitations, very interesting, functional and valuable things can be done. The challenge is to understand what works, what doesn’t and why, to know how to use the best tools, optimise their use and try to improve their performance for each specific business case.
What’s the future?
The future dream in this field is to arrive at methods that do not need human examples or, at least, to reduce their dependence significantly. We want machines that do not need millions of examples of labelled word-by-word sentences to learn.
It is already known that some methods allow machines to learn without needing examples. These are the methods behind the machines that play chess better than the great chess masters or those that beat the best gamers in the world in some video games. But can these methods be extrapolated to other areas of Artificial Intelligence, such as NLP? For example, can we reach machines that just by “observing” us talking, can understand what we say?

Alejandro Salamanca R – Lead Data Scientist

VISIT OUR KNOWLEDGE CENTER
We believe in democratized knowledge
Understanding for everyone: Infographics, blogs, and articles
Let’s tackle your business difficulties with technology
” There’s a big difference between impossible and hard to imagine. The first is about it; the second is about you “

Marvin Minsky, Professor pioneer in Artificial Intelligence